Unser Projekt BärGPT beschäftigt sich damit, wie ein KI-Assistent aufgebaut sein muss, damit er eine langfristige Arbeitserleichterung für die Beschäftigten darstellt. In unserer Devlog-Serie geben die CityLAB-Entwickler:innen Einblicke in technische Aspekte, Funktionen und Learnings aus der Entwicklung des KI-Prototyps.
Im ersten Teil ging es darum, wie BärGPT Verwaltungswissen vermittelt bekommt und welche Datenquellen dafür geeignet sind. Im zweite Teil zeigt Data Scientist Malte Barth, wie wir BärGPT beibringen, bei der Antwortgenerierung auf Quellen zu verweisen – und warum Transparenz entscheidend ist, um Vertrauen in KI-Systeme zu schaffen.

Lieber falsch antworten als gar nicht antworten?
In der Arbeit mit KI-Chatbots kann es häufig vorkommen, dass eine Antwort generiert wird, die wahlweise völlig falsch ist oder wie blind “geraten” wirkt. Dieses Phänomen nennt sich “Halluzination” und ist darin begründet, dass das zugrunde liegende KI-Modell nur eine bestimmte Menge an Daten während des Trainings “gesehen” hat und daher in anderen Kontexten ggf. nur eine gute “Vermutung“ abgeben kann. Außerdem ist der Wissensstand der verwendeten Modelle oft mehrere Monate veraltet, sodass neuere Entwicklungen oder aktuelles Zeitgeschehen gar nicht mit in die Antwort einbezogen werden können, ohne Anbindung an das Internet. Large Language Models (LLMs) sind so konzipiert, dass sie basierend auf den eingegebenen Worten eine möglichst wahrscheinliche Antwort generieren. Zusätzlich wird beim Training von LLMs die RLHF (Reinforcement Learning from Human Feedback) Methode verwendet. Bei dieser werden Zwischenversionen eines neuen KI-Modells einer bestimmten Gruppe von Nutzer:innen ausgespielt und diese können entscheiden welche generierte Antwort sie besser finden. Dies hat allerdings ebenso zur Folge, dass Antworten wie “Das weiß ich leider nicht.” schlechter bewertet werden, als selbstbewusste aber falsche Antworten.
Das fehlende aktuelle Wissen haben wir bei BärGPT durch Systemanweisungen versucht sichtbar zu machen, sodass unser KI-Modell bei bestimmten Themen wie aktuellen Geschehnissen oder Daten zu Personen des öffentlichen Lebens auf eine Internetsuche verweist. Diese Lösung ist nicht perfekt, aber hilft sehr dabei das Generieren von Falschinformationen zu verringern und die Nutzenden für das Problem zu sensibilisieren. Sollte BärGPT in zukünftigen Versionen auch direkt auf das Internet zugreifen können, wäre dieses Problem größtenteils gelöst.
Vertrauen schaffen: Wie BärGPT seine Quellen offenlegt
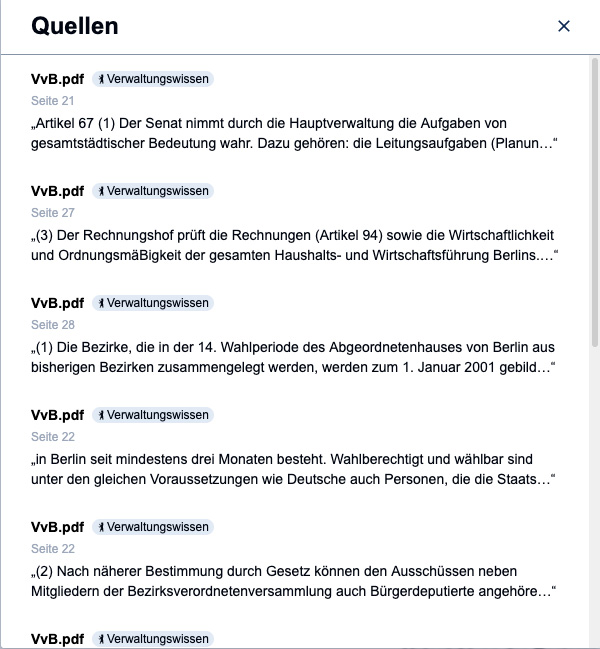
Wenn es darum geht mit Dokumenten zu arbeiten, die von den Nutzer:innen hochgeladen wurden bzw. sich Fragen auf Schriftstücke des Basiswissens von BärGPT beziehen, ist es gerade in der Verwaltung wichtig zu wissen, auf welcher Basis das LLM die jeweilige Antwort generiert hat. Deshalb haben wir ein neues Quellen-Feature für BärGPT entwickelt.
Dieses Feature macht es möglich bestimmte Textabschnitte, welche das KI-Modell genutzt hat, in einer Quellenliste an die generierte Antwort anzuhängen. Außerdem erhoffen wir uns dadurch gesteigertes Vertrauen in unsere Lösung seitens der Anwender:innen, da so bspw. konkrete Verordnungen und Gesetze zitiert und auf die Stelle im bereit gestellten Dokument verwiesen werden kann.
Wir hatten auch damit experimentiert, das Ganze über Fußnotenziffern zu lösen, sodass nach jedem Textabschnitt der Antwort des Chatbots eine kleine Zahl erscheint, die beim Darüberfahren mit der Maus die dort genutzte Textstelle anzeigt. Trotz intensiver Tests konnten Konsistenz und Qualität unsere Anforderungen nicht erfüllen. Dies kann viele mögliche Ursachen haben, darunter die vergleichsweise geringe Parameterzahl des von uns verwendeten Open-Source-KI-Modells von Mistral. Nichtsdestotrotz hoffen wir mit dieser Implementation einer Quellenliste bereits ein gesteigertes Vertrauen in die Antwortqualität unserer KI-Lösung in unserer Anwender:innengruppe erzeugen zu können.
Wie stellen wir sicher, dass die Quellen nicht ausgedacht sind?
Nun zur technischen Umsetzung dieser neuen Funktion: Im Großen und Ganzen verwenden wir für das Auffinden passender Textpassagen weiterhin RAG (Retrieval Augmented Generation) über unsere interne Vektorendatenbank. Die Suche erfolgt dabei entweder über die Dokumente, die aktiv dem Chat hinzugefügt wurden oder optional über die Basiswissendokumente, welche bereits im Vorfeld durch Admins hinterlegt wurden. Dabei werden die am besten zur Anfrage passenden Abschnitte dem KI-Modell als zusätzlichem Kontext zur Verfügung gestellt. Eben jene “Snippets” werden nun zusätzlich auch in der Quellenliste den Nutzer:innen angezeigt, anstatt nur im Hintergrund verwendet zu werden. Somit wird der Prozess der Antworterstellung noch transparenter.
In den folgenden Devlogs erfahrt Ihr, wie es mit diesem Feature und weiteren Funktionen weitergeht. Mehr Informationen zu BärGPT findet Ihr auf unserer Projektseite. Stay tuned!