BärGPT ist mehr als nur ein weiterer KI-Chatbot, es ist ein maßgeschneidertes Werkzeug für die Berliner Verwaltung. In diesem Artikel möchten wir einen Blick unter die Motorhaube werfen und zeigen, welche technischen Entscheidungen und Herausforderungen hinter der Entwicklung stehen. Von der Architektur über Tool-Calling bis hin zur Skalierung für potenziell zehntausende Nutzende geben wir Einblicke in die praktische Umsetzung. Wie wir bewährte KI-Technologien mit den spezifischen Anforderungen der Verwaltungsarbeit verbinden, erfahrt ihr in diesem technischen Deep Dive.
Mit Dokumenten arbeiten
Bei der Entwicklung von BärGPT stand für uns das Erleichtern der Arbeit mit Dokumenten in Vordergrund. Da wir bei Parla bereits mit einer großen Menge von Dokumenten des Berliner Abgeordnetenhauses verarbeitet haben, wussten wir, dass die dort verwendete Basistechnologie “Retrieval Augmented Generation“ (RAG) einen sinnvollen Startpunkt für BärGPT bilden würde, denn wir hatten dort bereits zeigen können, dass RAG auf viele tausende Dokumente skalieren und Anfragen schnell und genau beantworten kann.
Der Unterschied bestand nun für uns darin eine Hilfe für den Alltag der Beamt:innen Berlins zu schaffen, anstatt eine reine Abfrageplattform aufzubauen. Um das zu schaffen, haben wir uns früh in der Entwicklung an einem bekannten Bild orientiert – dem des Desktops zur Ablage von Dokumenten. Das ist ein entscheidender Unterschied von BärGPT zu vergleichbaren Chatbots. Dort kann man ebenfalls Schriftstücke innerhalb eines Chats hochladen. Doch diese verschwinden beim Starten eines neuen Gesprächs oder beim Öffnen der Website am nächsten Tag wieder. In der Verwaltungsarbeit wird jedoch über einen längeren Zeitraum mit den gleichen Dokumenten gearbeitet. Um ständiges wiederholtes Hochladen zu vermeiden, haben wir uns daher für eine persistente Dokumentenablage inklusive optionalen Ordnern zur besseren Sortierung entschieden. Von dort können die Dateien jederzeit von den Nutzer:innen zum Chat hinzugefügt werden und zur Weiterarbeit verwendet werden.
Manchmal braucht man aber gar kein Dokument als Referenz, sondern hat eine allgemeinere Anfrage, wie beispielsweise das Formulieren einer E-Mail zu einem bestimmten Thema. Auch diese Funktion unterstützen wir im Gegensatz zu anderen KI-Anwendungen, die speziell für die Verwaltung konzipiert wurden und nur starre Schaltflächen für Zusammenfassungen oder andere ähnliche Anfragen bieten. In unserer Vielzahl von Nutzerinnen-Tests hat sich herausgestellt, dass eine signifikante Menge von Verwaltungsmitarbeitenden den intuitiven Umgang mit KI-Chattools versteht und teilweise auch auf private Erfahrungen mit ähnlichen Produkten zurückgreifen kann. Für alle Nutzer:innen, die mit BärGPT ihre erste Erfahrung mit einem KI-Assistenten sammeln, haben wir zusätzlich umfangreiches Hilfs- und Schulungsmaterial erstellt – von Schritt-für-Schritt-Videoanleitungen über ein klassisches Handbuch bis zu FAQs.
Tool-Calling
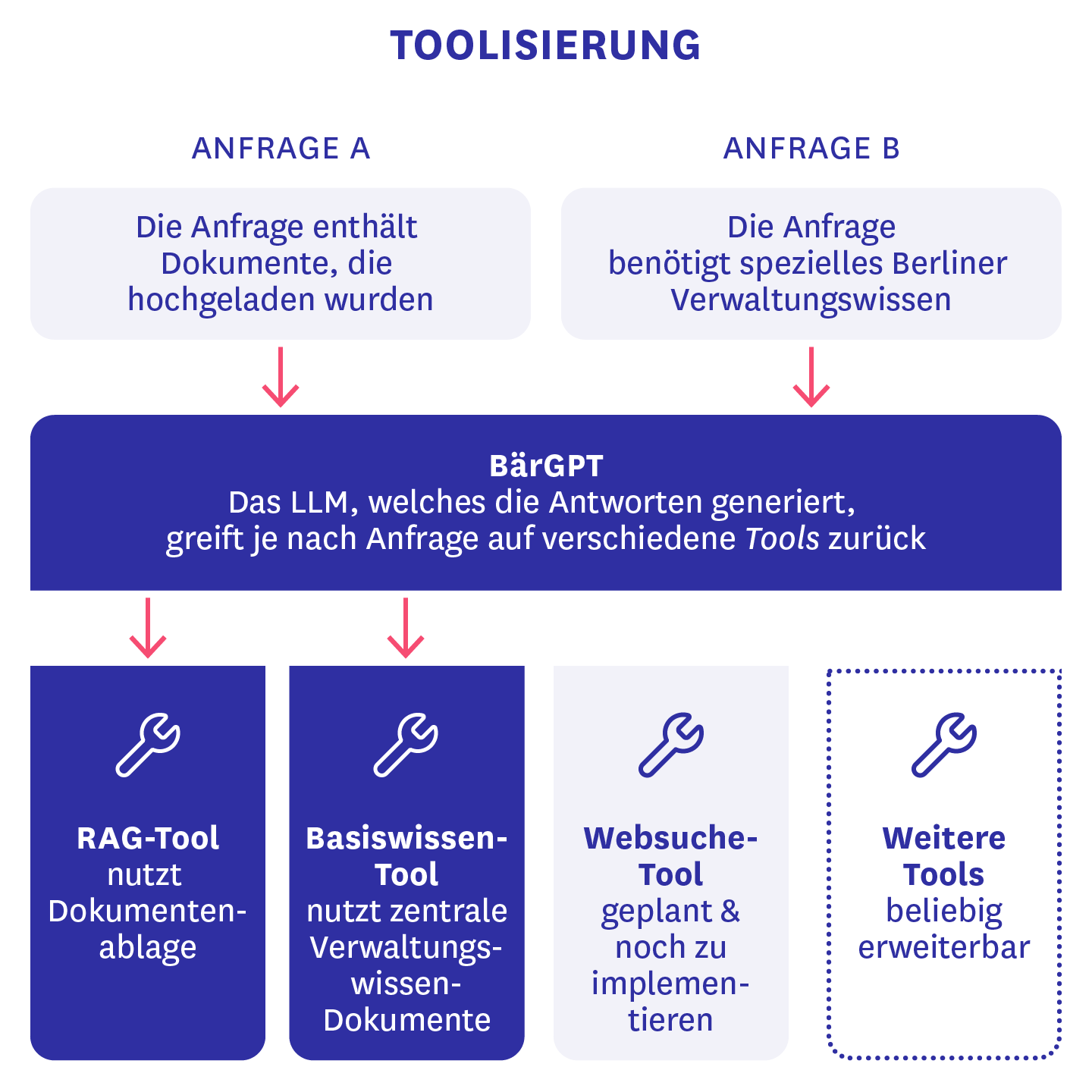
Um die Funktionsweise von BärGPT über einen einfachen Chatbot mit RAG-Anbindung hinaus zu erweitern, haben wir Tool Calling als Feature eingebaut. Das bedeutet, dass das Large Language Model (LLM), welches die Antworten von BärGPT generiert, eine Liste an Funktionen zur Verfügung hat, die es unter bestimmten Bedingungen ausführen soll. So haben wir aus dem RAG-Chat ein eigenes Tool gebaut, das immer verwendet wird, wenn Dokumente zum Chat hinzugefügt werden. Zusätzlich gibt es auch noch ein Basiswissenstool, welches das KI-Modell eigenständig nutzen kann, wenn es “vermutet”, dass für die gesuchte Antwort spezielles Berliner Verwaltungswissen benötigt wird, das über die Trainingsdaten des LLMs hinaus geht. In diesem Fall wird eine RAG-Suche über eine bestimmte Menge an durch Administrator:innen zuvor hochgeladenen Dokumenten, die für alle Nutzenden aus der Verwaltung eine Relevanz haben könnten, gestartet.
Der große Vorteil dieser Architekturentscheidung ist, dass durch diese “Toolisierung” in Zukunft weitere Funktionen wie beispielsweise eine Websuche einfach zu BärGPT hinzugefügt werden können und theoretisch auch von den Endnutzer:innen selbst ein- und ausgeschaltet werden können. Gerade die bisher noch fehlende Websuche hat uns teilweise kreativ werden lassen, was die Gestaltung unserer Systemprompts angeht. Um falsche Informationen zu aktuellen Ereignissen und öffentlichen Personen vorzubeugen, verweist BärGPT aktuell auf eine herkömmliche Internetsuche, bis wir diese Funktion auch selbst integriert haben.
Quellen und strukturierte Ausgaben
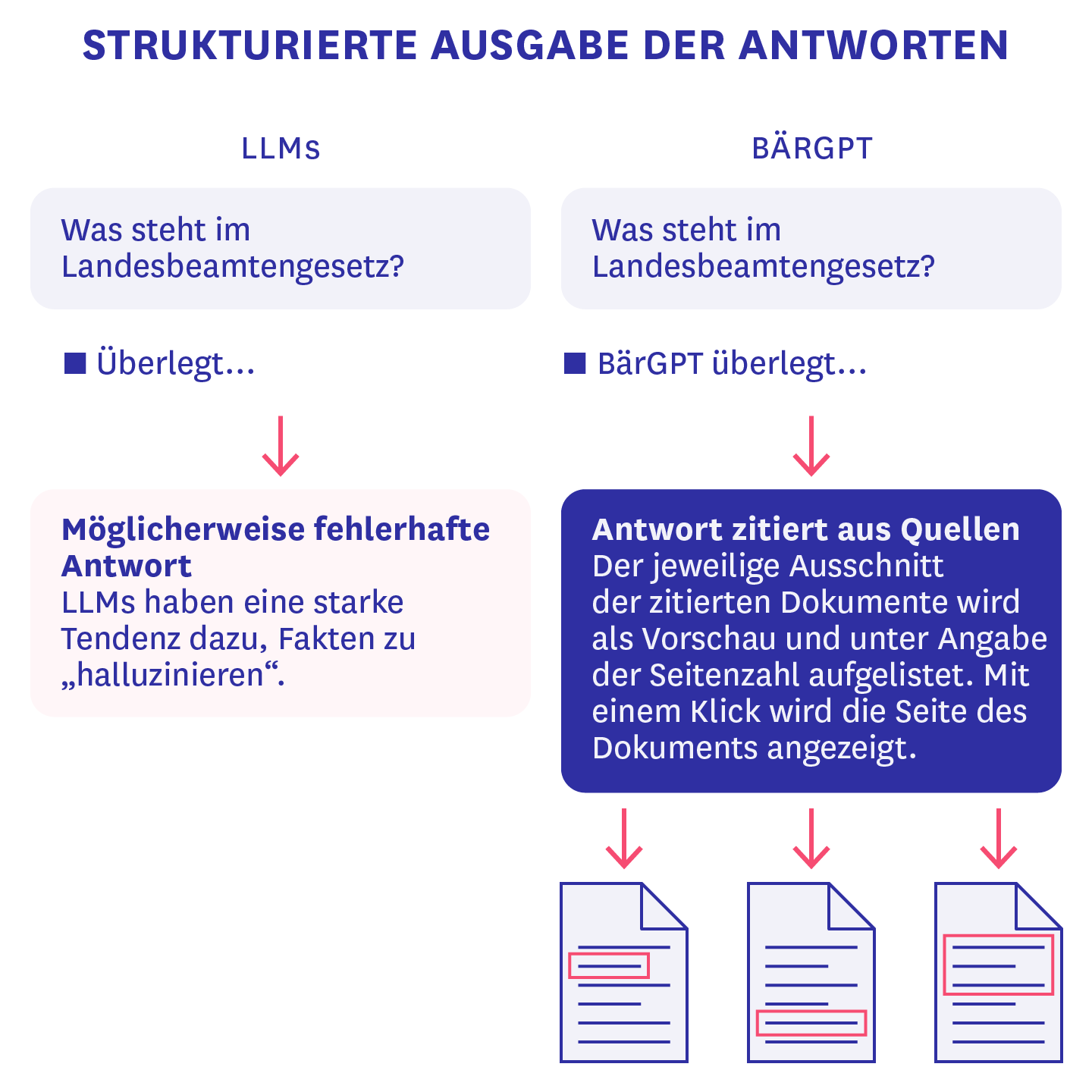
Eine weitere Funktion, die in unseren Tests oft nachgefragt wurde, sind Quellenangaben, da LLMs eine starke Tendenz dazu haben Fakten zu “halluzinieren”, also Unwahrheiten zu generieren und als Wahrheit darzustellen. Dazu nutzen wir relevante Zitate aus angegebenen Dateien in Kombination mit der Technik von “Structured Outputs” (strukturierten Ausgaben). Dadurch generiert das LLM hinter BärGPT nicht nur einen einzelnen zusammenhängenden Text, sondern ein JSON-Objekt, die zum einen die Textantwort auf die Anfrage der nutzenden Person enthält und zum anderen eine Liste von IDs, die mit Textabschnitten korrespondieren, die für die Erstellung der Antwort genutzt wurden. Dieses strukturierte Objekt wird außerdem gestreamed. Das bedeutet, dass man die ersten Wörter der Antwort bereits sieht, bevor das Objekt als Ganzes von der API des LLM-Anbieters zurückgegeben wurde. Dies kann in seltenen Fällen dazu führen, dass ein Teil des JSON-Objektes nicht korrekt generiert wird, weil zum Beispiel eine schließende Klammer fehlt, und infolgedessen die Quellenliste nicht angezeigt werden kann. Wir sind allerdings zuversichtlich, dass zukünftige KI-Modellversionen dieses Problem noch weniger häufig haben werden und, dass wir zusätzlich durch Anpassungen am Systemprompt iterativ diese Generationsfehler noch weiter verringern werden können.
Selbst-Hosten von Teilen der Infrastruktur
Da wir möglichst vielen Menschen im Probe-Echtbetrieb Zugang zu BärGPT verschaffen wollten und gleichzeitig größtmögliche Datensicherheit, sowie DSGVO-Konformität gewährleisten wollen, haben wir nach guten Lösungen für das Hosting gesucht. Aus diesem Grund haben wir unsere Datenbank auf eine deutsche BSI-C5-zertifizerte Cloud-Infrastruktur umgezogen. Dabei haben wir es geschafft unser Setup einer Produktions- und Entwicklungsdatenbank nachzubilden, dafür zu sorgen, dass Verbindungen zur Datenbank gesichert sind und wir sie weiterhin zur Verifizierung unserer Nutzer:innen verwenden können. Wir hoffen, dass die von uns gewählte Hardware dem großen Ansturm auf BärGPT standhalten kann, und werden das Anfragevolumen in den Anfangswochen genau beobachten, um allen eine möglichst verzögerungsarme Verwendung zu ermöglichen.
Skalierung und Stresstests
Da wir mit BärGPT als KI-Assistent für die Berliner Verwaltung potenziell zehntausende Benutzende erwarten, haben wir entsprechend höhere Ansprüche für die Skalierung und Verfügbarkeit gehabt als für unsere bisherigen Prototypen. Deshalb haben wir einige kritische Teile unserer Infrastruktur auf Skalierung getestet. Dazu haben wir Anfragelimitierungen von API-Anbietern so gut es ging hochgesetzt und zusätzlich eine interne Queue entwickelt, falls diese Limitierungen nicht ausreichen sollten, damit Anfragen zumindest mit geringer Verzögerung ausgeführt werden können, anstatt fehlzuschlagen. Außerdem haben wir diverse Optimierungen bei Prozessor- und Arbeitsspeichernutzung an unserem Backend durchgeführt, sowie eine automatische Skalierung dessen aktiviert.
Das Ganze haben wir dann noch durch sogenannte Stresstests auf Herz und Nieren geprüft, indem wir sukzessive mit der bekannten k6 Softwarebibliothek virtuelle Nutzende mit Beispieldokumenten und –anfragen auf unsere Testumgebung losgelassen haben.
Herausforderung: Langwierige Dokumentenverarbeitung
Auf eine besonders interessante Herausforderung sind wir beim Verarbeiten großer Dokumente mit viel Textinhalt gestoßen. Das hat zeitweise beinahe 10 Minuten für eine ca. 20 MB große Datei gedauert. Der größte Anteil hieran war das Erstellen der Embeddings für die einzelnen Textabschnitte. Was genau hat hier so lange gedauert?
Wir nutzen Markdown-basiertes Chunking für die Textabschnitte. Das bedeutet, dass wir zunächst den Text an Markdown-Überschriftselementen und dann an Abschnittsgrenzen aufteilen, um Textabschnitte oder “Chunks” zu generieren. Sollten diese zu groß für das Embedding-Modell sein, werden sie rekursiv in kleinere Einheiten aufgeteilt: Zunächst in Zeilen, dann Sätze und schließlich Wörter. Diese Einheiten werden so lange aneinandergereiht, bis das Tokenlimit überschritten wird. Dann wird die Zeichenfolge genutzt aus der Iteration davor, um Chunks zu erzeugen. In der alten Implementation haben wir dann Batches aus Chunks erzeugt, die zusammen genommen unter dem Tokenlimit liegen. Das Verarbeiten eines solchen Batches kann unterschiedlich lang dauern – von einigen wenigen bis über 20 Sekunden.
Dieses sequenzielle Abarbeiten der Batches war ineffizient, da die einzelnen Chunks völlig unabhängig voneinander waren. Deshalb haben wir diesen Vorgang parallelisiert, nachdem wir herausgefunden haben, dass wir über unsere Embedding-API nicht nur einen Batch pro Anfrage, sondern 512 Batches pro Anfrage schicken konnten. Zusätzlich haben wir die Generierung von einer Zusammenfassung des Dokuments, die bei entsprechender Größe auch einige Sekunden dauern kann, parallel zur Erstellung der Embeddings implementiert. Das hat signifikant Zeit eingespart, sodass das gleiche große PDF nun in weniger als zwei Minuten vollständig verarbeitet wurde.
Hier sind ein paar Logs, welche die Timings zeigen:


Die Architektur
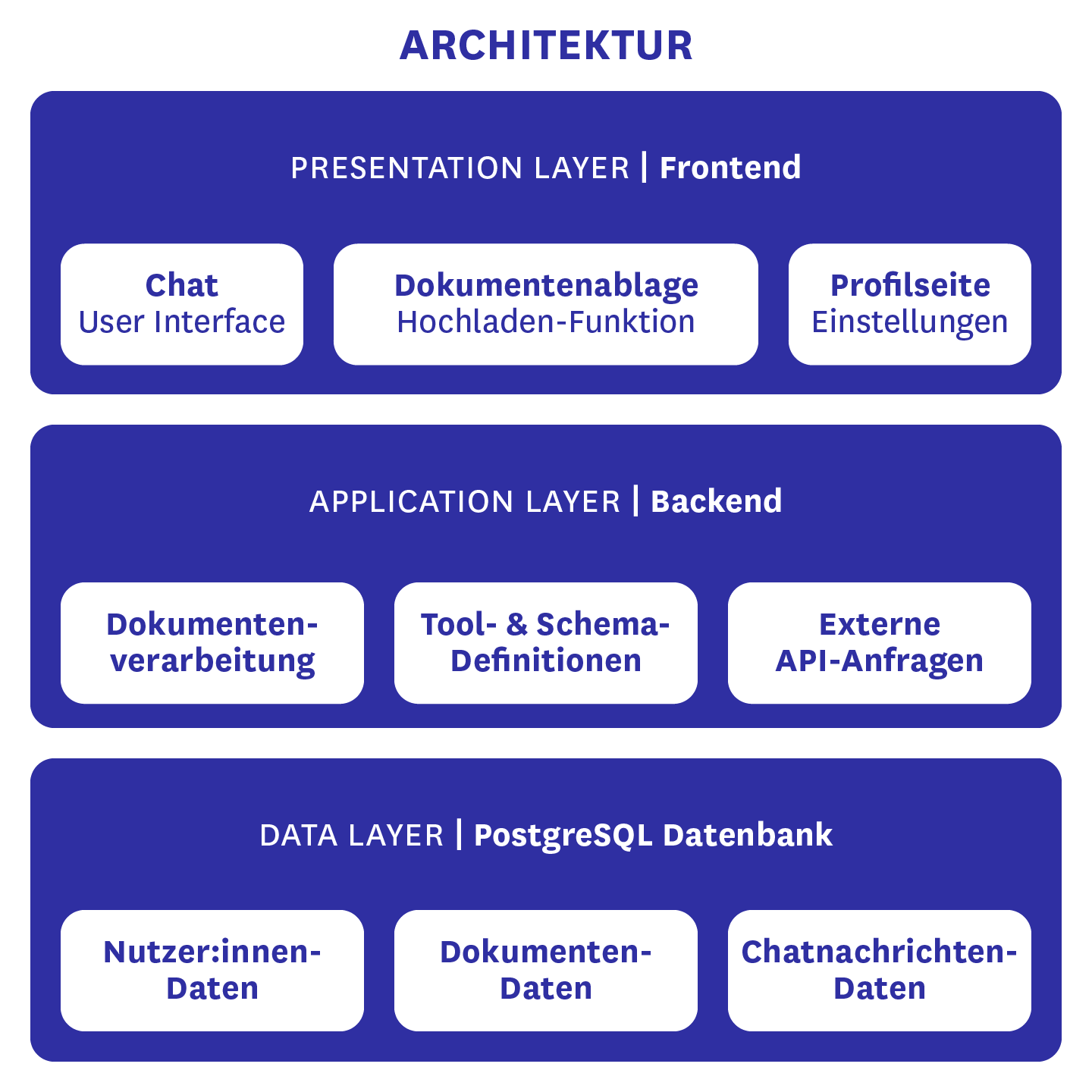
Wie im Architekturdiagramm zu erkennen ist die Datengrundlage von BärGPT eine Supabase-Instanz, die eine PostgreSQL-Datenbank beinhaltet, sowie einige zusätzliche Funktionen bereitstellt. Dazu gehören etwa die Authentifizierung von Nutzenden, sowie die E-Mail-Templates, welche wir für das Generieren von E-Mails nutzen. In der Postgres-Datenbank selbst liegen die Nutzendendaten wie Vor- und Nachname, E-Mail-Adresse, das verschlüsselte Passwort, sowie optional die Anrede und der Titel der Person. Außerdem enthält sie sämtliche Dokumentendaten, von dem Originaldokument, über den extrahierten Text, die daraus generierten Embeddings für die RAG-Suche, Zusammenfassungen der Dateien und weitere Metadaten. Schließlich finden sich dort auch die Chatverläufe von BärGPTs Anwender:innen, damit auf alte Chats jederzeit zugegriffen werden kann.
In unserem Backend werden vor allem externe API-Anfragen gestellt, wie an unser verwendetes LLM oder unseren Embedding-Anbieter. Ansonsten findet dort die Dokumentenverarbeitung statt, die es ermöglicht mit den hochgeladenen Dateien in Interaktion zu treten. Schließlich sind dort auch die von uns verwendeten Tools und Ausgabe-Schemata definiert und werden dem LLM zur Verfügung gestellt.
Unser Frontend ist für alles verantwortlich, was auf unserer Website gesehen werden kann. Dazu zählen das Chat-Interface, die Dokumentenablage, inklusive der Hochlade-Funktion neuer Unterlagen, und die Profilseite. In letzterer können persönliche Daten und das eigene Passwort geändert werden. Außerdem kann man dort sehen, auf welche Basisdokumente man aktuell Zugriff hat und man kann auswählen, ob man gesiezt oder geduzt werden möchte. Für Adminstrator:innen gibt es noch eine zusätzliche Ansicht, in welcher neue Basiswissensdokumente hochgeladen werden können. Diese Ansicht ist aktuell Entwickler:innen des CityLABs vorbehalten. Wir planen aber in Zukunft auch Einzelpersonen aus bestimmten Häusern Zugang dazu zu geben, um das Basiswissen ihres jeweiligen Hauses oder ihrer Abteilung befüllen zu können.
Ihr wollt auf dem Laufenden bleiben? Mehr Updates zu BärGPT gibt es auf unserem Blog und im öffentlichen BärGPT-Hilfecenter.