Our project BärGPT explores how an AI assistant must be designed to provide long-term relief and support for employees in their daily work. In our devlog series, the CityLAB developers offer insights into the technical aspects, features, and learnings from developing the AI prototype.
The first part focused on how BärGPT is trained to understand administrative knowledge and which data sources are suitable for that purpose. In the second part, data scientist Malte Barth demonstrates how we teach BärGPT to reference sources when generating answers — and why transparency is crucial for building trust in AI systems.

Better to give the wrong answer than no answer at all?
While working with AI chatbots it can often occur that an answer gets generated that’s either completely false or seems to be randomly ‘guessed’. This phenomenon is known as ‘hallucination’ and stems from the fact that AI models only have ‘seen’ a certain amount of data during training and therefore potentially can only make a good ‘assumption’ in different contexts. Furthermore, the state of knowledge of the model is often many months old, which means that new developments or recent events can’t be included in the answer generation in the first place without an internet connection. Large language models (LLMs) are designed to generate the most likely answer given the words entered. Additionally, during the training of LLMs the RLHF (reinforcement learning from human feedback) method is used. There, intermediate versions of new AI models are shown to a certain group of users who can decide which answer they prefer. This often leads to answers like ‘I don’t know.’ being rated worse than confidently wrong answers.
We tried to make this missing knowledge visible with BärGPT with system prompts, so that the AI model recommends an internet search for certain topics such as recent events or data about public people. This solution isn’t perfect but helps a lot to mitigate the generation of fake information and to sensitize users to the problem. If BärGPT should gain access to the internet in future iterations, this problem will be largely solved.
Gaining trust: How BärGPT discloses its sources
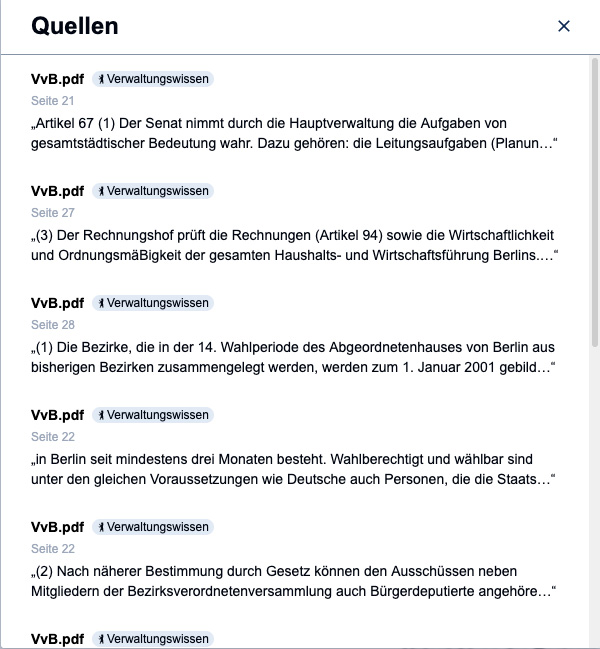
For use cases like working with documents that users uploaded or questions concerning documents of BärGPT’s base knowledge, especially in the public administration it’s important to know what the original source of the answer was. That’s why we developed a new ‘sources feature’ for BärGPT.
This feature allows certain text snippets, that were used by the AI model, to be appended to the generated answer as a list of sources. Additionally, we hope to further gain trust with our users in our solution as this enables concrete laws and regulations to be cited and to be referred to the relevant sections in the document provided.
We also experimented with adding footnotes to the answer so that a small number would appear after every paragraph which would show the used text section on hover. Despite intense tests, the consistencyand quality did not meet our bar of acceptance. This can have multiple causes, among them the comparatively small amount of parameters of our used open source AI model by Mistral. Nonetheless we hope that this implementation of a list of sources will already lead to a larger trust in the quality of the answers of our AI solution within the group of users.
How do we ensure that the sources are not hallucinated?
Now for the technical details of this new functionality: In general we use RAG (Retrieval Augmented Generation) for finding matching text snippets in our internal vector database. This search is either within the documents that were actively added to the chat by the user or optionally within the base knowledge docuements admins uploaded beforehand. The best fitting sections to the user query are being fed to the AI model as additional context. These snippets now being displayed additionally in the list of sources for the users to see instead of only being used in the background. This makes the process of answer generation more transparent.
In the following devlogs, you will learn how this feature and other functions will develop. You can find more information about BärGPT on our project page. Stay tuned!