“Ich habe mir das Paradies immer als eine Art Bibliothek vorgestellt.” – Jorge Luis Borges
PSSSSSTTT!! Diesen Text musst du dir in einem Flüsterton vorstellen, denn wir befinden uns gedanklich in einer Bibliothek. Bibliotheken sind nicht nur ein Ort des Wissens, der Inspiration und des intellektuellen Wachstums, sondern auch der Begegnung und des Austausches aller Altersgruppen. Die Bibliothek ist ein Ort, an dem man in die Welt der Bücher und Gedanken eintauchen kann, und ein unersetzliches Instrument für das Lernen und die Forschung. Die Bibliothek enthält jedoch nicht nur fremdes Wissen, sondern kann auch eine Unmenge an Daten über sich selbst preisgeben! Über das zentrale Verbundservicezentrum (VSZ) der Zentral- und Landesbibliothek (ZLB) enthalten alle Bibliotheken Berlins Informationen über die Medienausleihungen in ihrem Bezirk. Vor einem halben Jahr wurde das Team der Open Data Informationsstelle (ODIS) von dem Leiter der Janusz-Korczak-Bibliothek in Pankow angesprochen, ob diese Daten nicht auch für das Open Data Portal interessant sein könnten und veröffentlicht werden sollten.
Wir haben Lisa Stubert und Klemens Maget von ODIS ein paar Fragen zu diesen Daten gestellt, um zu erfahren, was sie spannendes damit angestellt haben!
Warum sind diese Bibliotheksdaten auch für die Stadtgesellschaft relevant?
Klemens: “Bibliotheken sind als Orte des Lernens und Zusammenkommens zentrale Orte für die Stadtgesellschaft und bieten für unterschiedliche Gruppen wie Personen mit Fluchterfahrung oder Senioren ein vielfältiges Angebot. Durch die Öffnung und Auswertung der Bibliotheksdaten profitiert die Stadtgesellschaft direkt, da die Bibliotheken die Bedarfe der Bürgerinnen besser verstehen und ihr Angebot entsprechend anpassen können. Fragen Kinder und Jugendliche zum Beispiel vor allem nach digitalen Medien, würde es Sinn machen, sich in diesem Bereich besser aufzustellen. Auch können die Daten eine Antwort auf die Reichweite der einzelnen Bibliotheksstandorte geben und damit auf die Frage, ob die bestehenden Standorte alle Kieze erreichen oder Bedarf an neuen/mobilen Standorten besteht. Bibliotheken sollen schließlich der gesamten Stadtgesellschaft zugutekommen.”
Mithilfe der offenen Daten können also gezieltere Analysen vorgenommen werden, um beispielsweise das Nutzungsverhalten oder die Reichweite der einzelnen Bibliotheksstandorte auszuwerten.
Aber enthalten die Daten auch persönliche Informationen über die Nutzer:in?
Lisa: “Ja, die Ausleihdaten sind ein gutes Beispiel dafür, dass Datensätze sehr persönliche Informationen enthalten können, durch eine vorgeschaltete Anonymisierung aber soweit verarbeitet werden können, dass sie keine Rückschlüsse auf Einzelne mehr zulassen und trotzdem noch allgemein spannende Aussagen ermöglichen. Stell dir zum Beispiel vor, du hast einen Nachbarn von dem du weißt, dass er 32 ist und er erzählt dir, dass er gestern in der Bibliothek war. In dem Ausleihdatensatz ist die Information enthalten, in welcher sogenannten Teilverkehrszelle die ausleihende Person wohnt, das ist eine Raumeinheit, mit der die Verwaltung arbeitet. Also quasi wie ein Kiez. Einige dieser Verkehrszellen haben gar nicht mal so viele Einwohner. Du könntest nun, wenn der Datensatz dann veröffentlicht wurde, nachgucken, was in deiner Teilverkehrszelle so geliehen wurde. Wenn da jetzt nur eine einzige Ausleihe von einem 32 jährigen verzeichnet ist, dann kannst du theoretisch daraus schließen, dass diese Ausleihe zu deinem Nachbarn gehört. Das verletzt natürlich die Persönlichkeitsrechte, wenn er nicht möchte, dass du seine Vorliebe vor Groschenromane kennst. Deswegen wurden bestimmte Informationen im Datensatz generalisiert.”
Wie der Übergang von sensiblen zu Open Data konformen Daten geklappt hat, kannst du in diesem Blogbeitrag nachlesen.
Die Bibliotheksdaten wurden mit dem Open Source Tool Grafana visualisiert. Grafana ist eine plattformübergreifende Anwendung zur grafischen Darstellung von Daten aus verschiedenen Datenquellen. Warum habt ihr euch für Grafana entschieden?
Klemens: “Mit Grafana können wir aus den Daten in wenigen Schritten ein Dashboard generieren und die Daten visualisieren. Zusätzlich können wir Datenbankabfragen schreiben und die Resultate grafisch darstellen, beispielsweise als Diagramme oder Karten. Der Vorteil von Grafana liegt darin, dass es ein bisschen wie ein Baukasten funktioniert. Wir bzw. die Stadtteilbibliothek können so niedrigschwellig weitere Abfragen und Auswertungen oder auch interne Dashboards erstellen. Dadurch, dass Grafana ein Open Source Tool ist, können auch weitere Bezirke eigene Instanzen aufsetzen und eigene Dashboards bauen.”
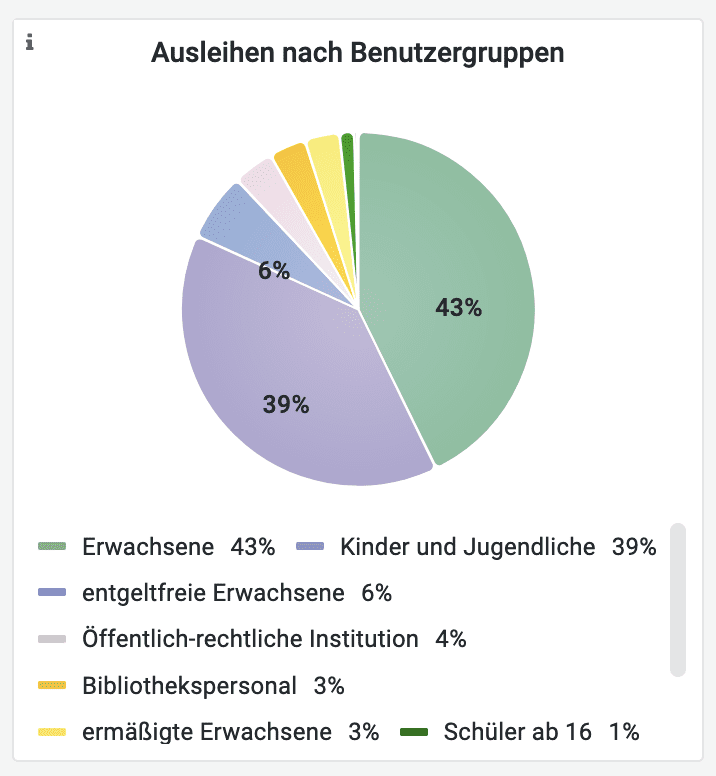
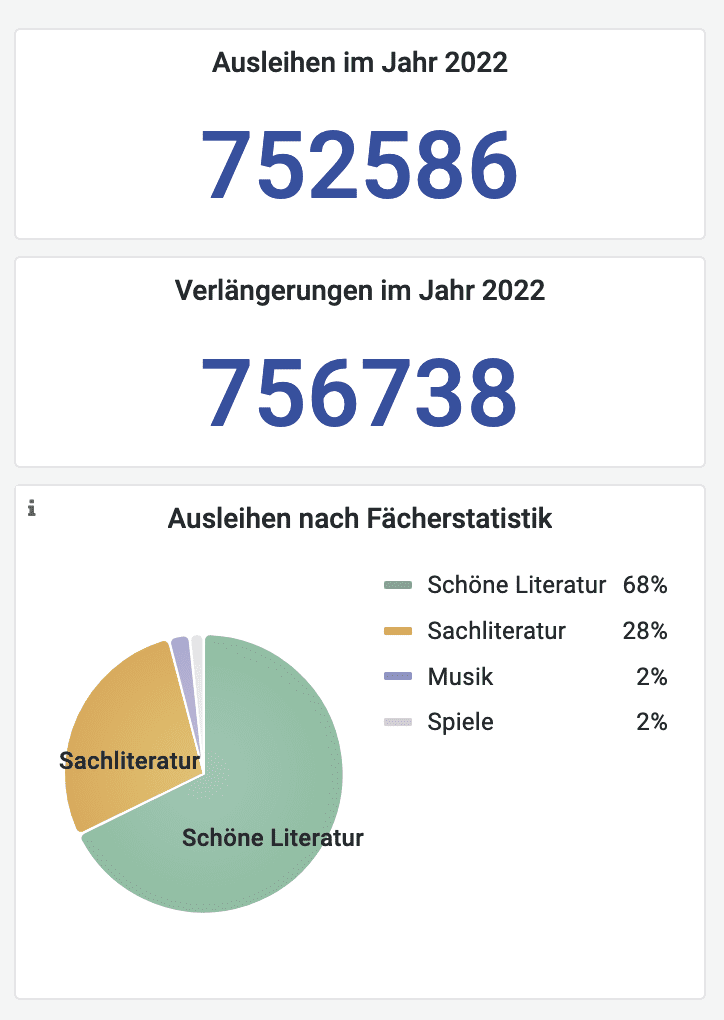
Die visualisierten Daten warten nur darauf, erkundet zu werden! Welcher Roman wurde im letzten Jahr am häufigsten entliehen? Wer ist die beliebteste Autorin? Welche Altersgruppen nutzen das Bibliotheksangebot am häufigsten? Und wann werden Medien über das Jahr gesehen am meisten nachgefragt? Diese und viele weitere Fragen können auf Grundlage von Daten zu Ausleihen für das Jahr 2022 beantwortet werden. Das Dashboard zeigt exemplarisch, welche Auswertungen anhand der Daten möglich sind.
Hier geht es zum Dashboard:
Liebe Lisa, eine letzte Frage, was liest du denn gerade?
Lisa: “Also, um ehrlich zu sein, ich lasse mir gerade vorlesen: Klara und die Sonne von Nobelpreisträger Kazuo Ishiguro. Es geht um eine dystopische Zukunftsvision, in der starke KIs zum Alltag gehören. Laut Dashboard wurde das Buch in Pankow letztes Jahr 48 mal ausgeliehen. Scheint also noch ein paar mehr Leute interessiert zu haben. Das sind allerdings nur ⅓ so viele Ausleihen wie die beliebteste Ausgabe des Lustigen Taschenbuchs. Vielleicht bin ich inspiriert und lese das als nächstes!”