“Das Bild vom Mann als Prototyp des Menschen ist grundlegend für die Struktur unserer Gesellschaft. Es ist eine alte, tief verwurzelte Tradition, die so weit reicht wie die Theorie der menschlichen Evolution selbst.” So beginnt Caroline Criado-Perez ihr Buch “Unsichtbare Frauen“, in dem sie den Gender Data Gap beschreibt, eine Datenlücke, die die systematische Auslassung geschlechtsspezifischer Daten aufzeigt. Diese Datenlücke führt zu einer unzureichenden Erfassung und Darstellung der Lebensrealitäten von Frauen und anderen Geschlechtern – mit weitreichenden Folgen in unserer datengetriebenen Welt. Unsere Kollegin Ester Scheck von der Open Data Informationsstelle (ODIS) hat sich mit der Verbindung zwischen dem Gender Data Gap und offenen Daten Berlins auseinandergesetzt und berichtet in diesem Interview von den Auswirkungen des Gender Data Gap und Möglichkeiten, diese Lücke zu schließen.

1. Was sind die Folgen des Gender Data Gap?
Ester: “Der Gender Data Gap ist eine Datenlücke, die fehlende Daten in Bezug auf geschlechtsspezifische Themen und Perspektiven beschreibt – und damit ist sie auch eine allgemeine Wissenslücke! Daten fehlen insbesondere zu den Lebensrealitäten von Frauen und queeren Personen. Männer hingegen wurden und werden als Norm betrachtet und sind mit ihrer Perspektive in der Datenlandschaft überrepräsentiert, das reicht von medizinischer Forschung bis hin zu Produkttestings. Konkret kann das dazu führen, dass Lösungen, die auf diesen Daten basierend entwickelt werden, für Frauen und queere Personen einfach nicht (gut) funktionieren. Beispielsweise orientieren sich die meisten Crashtest-Dummys für die Simulation von Autounfällen an männlichen Körpermaßen. Sicherheitsvorkehrungen im Auto sind deshalb weniger an weibliche Körper angepasst und Frauen sind auch statistisch gesehen einem höheren Verletzungsrisiko ausgesetzt.”
2. Inwiefern können geschlechtsspezifische Daten die Gleichberechtigung fördern?
Ester: “Man unterscheidet zwischen drei Arten von Gender Data und jede Art trägt auf andere Weise zur Gleichberechtigung bei:
- Daten, die geschlechterdifferenziert erhoben und analysiert werden, durch die Unterschiede zwischen den Geschlechtern sichtbar gemacht werden können. Diese Daten unterstützen die Identifikation von Handlungsbedarfen und ermöglichen das Monitoring von Gleichstellungszielen.
- Daten zu Themen, die insbesondere Mädchen und Frauen betreffen – zum Beispiel Sorgearbeit, weibliche Gesundheit oder sexualisierte Gewalt – und die damit bei der Entwicklung von Lösungen für diese Zielgruppe helfen.
- Daten, die die Wirkung des sozialen Geschlechts (Gender) und von Geschlechternormen auf die Geschlechter zeigen und dadurch Strukturen sichtbar machen, die der Gleichberechtigung im Wege stehen.“
3. Warum fehlen diese Daten und wie könnte unser Umgang mit Daten verbessert werden?
Ester: “Das Fehlen solcher Daten ist nicht zufällig, sondern in unserer patriarchalen Gesellschaft strukturell bedingt. Ein Bewusstsein dafür ist Voraussetzung für den diskriminierungssensiblen Umgang mit Daten. Gleichzeitig unterstützt die Erhebung solcher Daten die Gleichberechtigung verschiedener Geschlechter. Meiner Meinung nach könnten und sollten alle Daten, die irgendwie in Verbindung mit natürlichen Personen stehen, darauf untersucht werden, ob es geschlechtsspezifische Unterschiede gibt, sei es bei Auswirkungen von Umweltkatastrophen oder der Verträglichkeit von Medikamenten.”
4. Wie schätzt du die Verbindung zwischen Open Data und Gender Data ein?
Ester: “Es gibt viele Stimmen, die den Nutzen von offenen Daten beschreiben, und einige Stimmen, die auf die Bedeutung von Gender Data hinweisen. In Kombination miteinander ist meiner Recherche nach abgesehen von einzelnen Datenveröffentlichungsprojekten bisher jedoch wenig passiert.
Dabei können sich die beiden Konzepte gegenseitig bereichern und die jeweiligen Vorteile verstärken: Offene Daten werden wertvoller, wenn sie bewusst diverse Perspektiven und Lebensrealitäten beschreiben. Die Potenziale von Gender Data für die Gleichberechtigung können noch besser ausgeschöpft werden, wenn die Daten auch außerhalb der datenerhebenden Institution analysiert und genutzt werden können. Dies erhöht die Transparenz und es ergeben sich neue Möglichkeiten zur Beteiligung und Kollaboration.”
5. Kannst du einige konkrete Beispiele nennen, bei denen die geschlechtsspezifischen Unterschiede durch Daten sichtbar werden?
Ester: “Der Gender Datenreport der Senatsverwaltung für Arbeit, Soziales, Gleichstellung, Integration, Vielfalt und Antidiskriminierung liefert hier einige Beispiele. Diese machen auch deutlich: Es geht bei Gender Data nicht darum, zu belegen, dass es Frauen schlechter geht als Männern. Von geschlechtsspezifischen Daten profitieren wir als ganze Gesellschaft, da Diskriminierung sichtbar wird und Folgen sowie Ursachen zielgruppengerecht angegangen werden können.
Spannend sind außerdem nicht nur solche Beispiele, die sich direkt auf Personen beziehen, sondern auch Themen, die sich aufgrund der verschiedenen Lebensrealitäten unterschiedlich auf Männer und Frauen auswirken. Beispielsweise können finanzielle Förderungen für Sportvereine mit Sportarten, die aufgrund gesellschaftlicher Normen vor allem von Jungs ausgeübt werden, Mädchen benachteiligen. Leider gibt es dazu noch keine Daten und Auswertungen für Berlin, aber es zeigt, dass der Geschlechterbezug von Daten häufig nicht direkt sichtbar ist.”
6. Welche Daten hast du dir im Zuge deiner Forschungsarbeit angesehen und wie bist du dabei vorgegangen?
Ester: “Ich habe mir die Metadaten im Berliner Open Data Portal angesehen und auf den Geschlechterbezug hin untersucht. Metadaten sind Informationen, die einen Datensatz beschreiben, also zum Beispiel der oder die Herausgeber:in, Titel, Tags, Beschreibung und Aktualisierungsdatum. Diese Daten können über die CKAN-API – das ist eine standardisierte Programmierschnittstelle des Datenportals – abgerufen werden.
Zum Zeitpunkt meiner Analyse im Mai umfasste das Datenportal über 3.000 Datensatzeinträge, aus denen ich zuerst die Einträge herausfiltern musste, die sich auf natürliche Personen beziehen, um den direkten Genderbezug zu untersuchen. Für diese Einträge wurden Titel, Beschreibung und Tags auf verschiedene Gender-Stichworte geprüft: Frau/Mann, weiblich/männlich, Gender, Geschlecht. Taucht mindestens eins dieser Stichworte auf, nehme ich an, dass der dazugehörige Datensatz einen Genderbezug aufweist.
Um darüber hinaus einen Eindruck zu bekommen, welche Art von Eintrag eine Gender-Referenz hat, habe ich die Kategorien, Herausgeber:innen und Tags analysiert. Die Abfrage der API und die Untersuchung der Daten habe ich in Python programmiert, da hat mich teilweise auch meine Kollegin Lisa unterstützt. Für Details zum Vorgehen ist das Skript online abrufbar und der Code darf auch gerne für ähnliche Analysen weiter verwendet werden.“
7. Was haben deine Analysen ergeben?
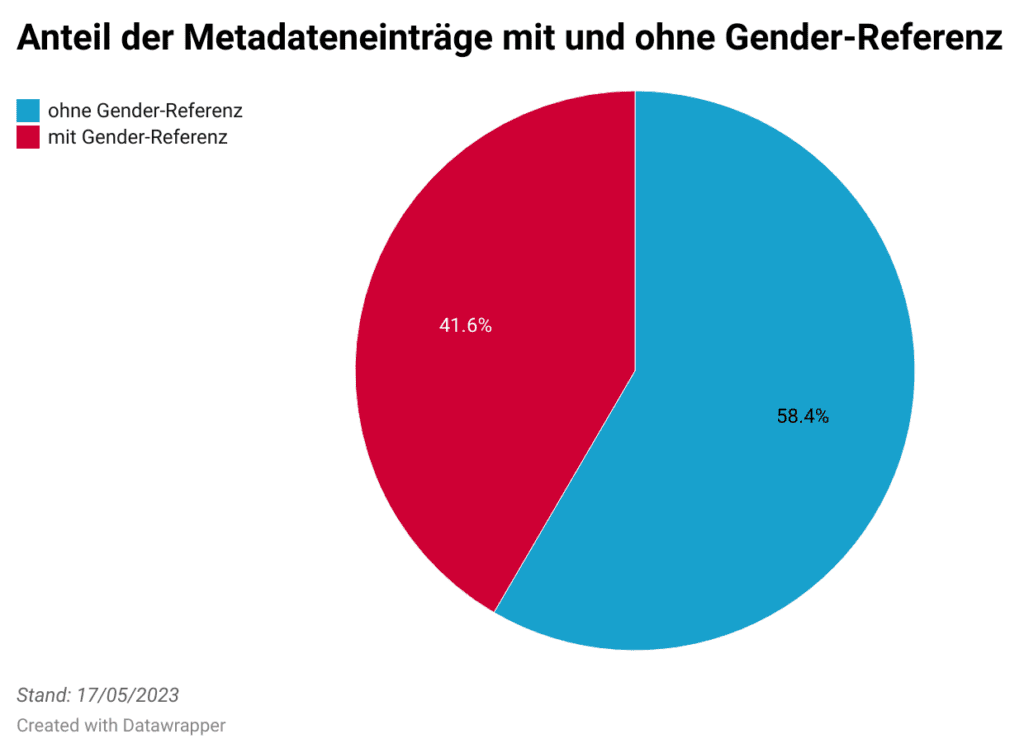
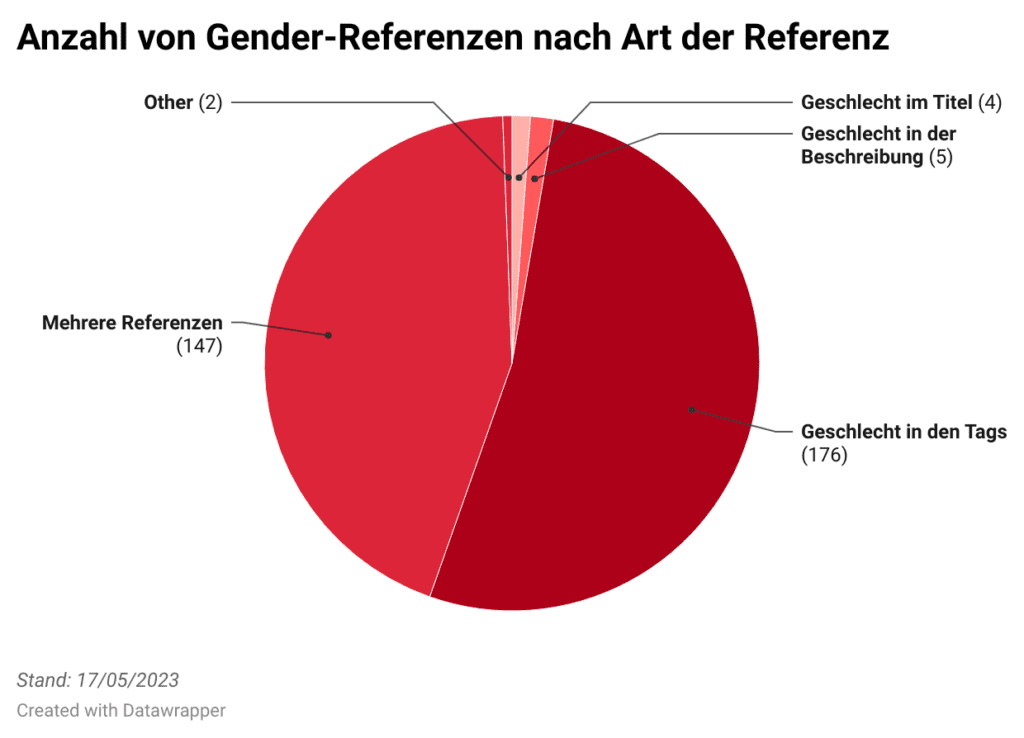
Ester: “Etwa ein Viertel der Einträge im Datenportal bezieht sich auf natürliche Personen und davon enthalten 41,6 Prozent eine Gender-Referenz. Leider gibt es dazu (noch) keine Vergleichswerte oder Richtwerte, deshalb ist es schwierig, diese Zahl zu bewerten. Aufschlussreicher ist da ein Blick auf die Art der Gender-Referenzen und die Kategorien und Herausgeber:innen. Mehr als 95 Prozent der Einträge enthalten das Stichwort “Geschlecht”. Die anderen Stichworte kommen äußerst selten vor – insbesondere Gender, das soziale Geschlecht, scheint noch wenig Aufmerksamkeit zu bekommen.
Zudem ist die große Mehrheit der Einträge mit Geschlechterbezug den Datenportal-Kategorien “Gesundheit” und “Sozialleistungen” zugeordnet, diese werden von der Senatsverwaltung für Wissenschaft, Gesundheit, Pflege und Gleichstellung veröffentlicht. Sie stammen also aus dem Gesundheits- und Sozialinformationssystem (GSI) der Senatsverwaltung. Auffällig ist, dass an zweiter Stelle der Herausgeber:innen die Senatsverwaltung für Stadtentwicklung, Bauen und Wohnen steht, deren identifizierte Datensatzeinträge jedoch keine Art von Gender-Referenz aufweisen. Dies könnte darauf hinweisen, dass in diesem Kontext Gender Data gestärkt werden sollte.
Dabei ist aber ganz wichtig zu beachten: die Analyse beruht rein auf den gegebenen Metadaten und nicht auf den Datensätzen selbst. Die Metadaten im Datenportal werden händisch von unterschiedlichen Personen oder automatisch aus anderen Portalen (Bsp. GSI, FIS-Broker) eingetragen und unterscheiden sich somit in Qualität und Umfang. Dass Datensatzeinträge im Stadtbaukontext, welche häufig Geodatensätze sind und über den FIS-Broker veröffentlicht werden, keine Gender-Referenz aufweisen, kann also auch an dem Import der Metadaten liegen.
Ich hätte die Analyse gerne direkt auf die Datensätze angewendet, anstatt nur die Metadaten zu untersuchen, doch aufgrund der Heterogenität und des Umfangs war dies im Rahmen meines Forschungsprojekts leider nicht möglich.”
8. Was könnte deiner Meinung nach bei der Erhebung der Daten verbessert werden?
Ester: “Die Erhebung von geschlechtsspezifischen Daten ist, denke ich, von Kontext zu Kontext recht unterschiedlich und durchaus herausfordernd. Es ist wichtig, bei der Erhebung sensibel und verantwortungsvoll zu handeln – und sich bestenfalls folgende Fragen zu stellen: Welche Geschlechtsidentitäten abseits von den binären Geschlechtern Frau und Mann müssen mitbetrachtet werden? Geht es eigentlich um das biologische Geschlecht (sex) oder um das soziale Geschlecht (gender)? Wie können Fremdzuschreibungen umgangen werden? Wie können diese Daten erhoben werden ohne gleichzeitig Diskriminierung und Stigmatisierung zu manifestieren?
Welche anderen “Kategorien” sollten in einem größeren Kontext analysiert werden, um weitere Diskriminierungsformen wie Rassismus oder Ableismus und Überschneidungen dazwischen (Stichwort Intersektionalität) quantitativ sichtbar zu machen? Wo sind vielleicht quantitative Erhebungen nicht geeignet? Und wie können diese personenbezogenen Informationen verantwortungsvoll genutzt und veröffentlicht werden? All diese Fragen zur Datenerhebung beschreiben nochmal ein ganz anderes, großes Feld, in dem beispielsweise Forschung in den Gender Studies schon großartige Arbeit geleistet hat.”
9. Wo kann ich mehr dazu lesen?
Ester: „Ich kann folgende Bücher zum Thema empfehlen:
- https://carolinecriadoperez.com/book/invisible-women/
- https://www.dumont-buchverlag.de/buch/endler-das-patriarchat-9783832170912/
- https://mitpress.mit.edu/9780262044004/.“
Vielen Dank Ester für die Einblicke in deine Forschungsarbeit! Mehr Informationen gibt es in diesem Blogbeitrag der Open Data Informationsstelle.