Gieß den Kiez, unsere Plattform für die Berliner Gieß-Community, war einer der frühen Prototypen, den wir im Frühjahr 2020 im CityLAB veröffentlichten. Seitdem haben sich auf der Plattform über aktiv gießende 3.200 Personen registriert, die die Berliner Stadtbäume mit über 1.6 Millionen Liter gegossen haben.
Dieser beeindruckende Einsatz und das begeisterte Feedback motivierten uns, die Plattform über die vergangenen Jahre immer weiter zu pflegen. Auch diese Jahr nahmen wir uns die Zeit, neue Funktionen und Verbesserungen in unsere Entwicklungs-Sprint “Herbstputz” umzusetzen. Für die eine Woche Sprint, die wir dafür eingeplant hatten, haben wir uns einen besonders großen Brocken vorgenommen: Die Ladezeiten von Gieß den Kiez zu verbessern.
Als wir die Plattform 2020 veröffentlichten, war sie als Prototyp konzipiert und entwickelt worden. Ecken und Kanten waren deshalb für uns akzeptabel und die langen Ladezeiten waren ein Umstand, der uns zwar nicht glücklich machte, aber durch die vielen Mehrwerte des Prototypen nicht so schwer wog. Nun sind wir einige Jahre weiter und das Projekt ist aus den Kinderschuhen heraus- und mittlerweile zu einer beachtlichen Community herangewachsen. Deshalb haben wir uns vorgenommen, uns den Ladezeiten richtig anzunehmen.
Warum hatte Gieß den Kiez so lange Ladezeiten?
Die Plattform zeigt den Großteil der 800.000 Berliner Straßen- und Anlagenbäume. So viele Bäume auf einer Web-Karte darzustellen, ist ressourcenintensiv und kann dauern, besonders bei älteren Endgeräten oder schlechten Internetverbindungen. Unser technischer Ansatz in 2020 war nicht ideal. Die Daten der Bäume wurden in einer CSV-Datei gespeichert, einem Format ähnlich einer Excel-Tabelle. Diese Datei musste bei jedem Aufruf der Karte geladen, weiterverarbeitet und gerendert werden.
Unser Ansatz hätte gut funktioniert – jedoch nur bei kleineren Datensätzen. Es macht einen grossen Unterschied, ob man eine CSV-Datei mit 800.000 Zeilen verarbeitet oder eine mit Hunderten oder wenigen Tausend. Doch auch für große Datenmengen mit Millionen Datenreihen gibt es Lösungen. Ein üblicher Ansatz ist das Rendern der Daten über sogenannte “Tiles”. Besonders “Vector Tiles” sind geeignet, um 800.000 Einzelpunkte auf einer Karte darzustellen.
Was sind Vector Tiles?
Hier wird es etwas technisch.
Bei Vector Tiles handelt es sich um eine Sammlung von quadratischen Einheiten, die in einzelnen Dateien gespeichert und von einer Kartenanwendung aufgerufen werden können.
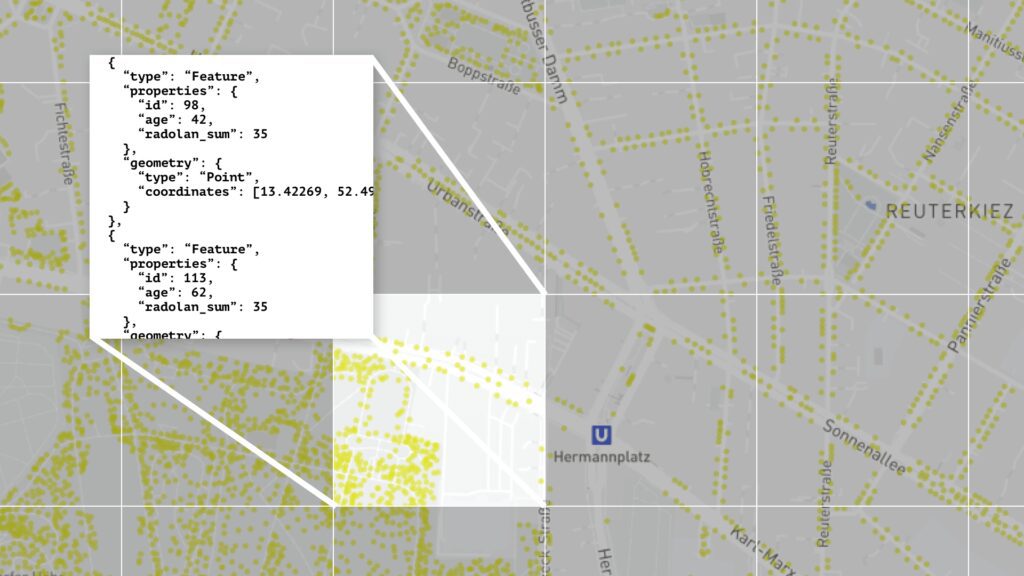
Vereinfacht gesprochen könnte man sagen, dass eine Tile-Einheit beispielsweise einen quadratischen Kartenausschnitt von Berlin-Kreuzberg mit Koordinaten und Informationen über alle Bäume in diesem Ausschnitt enthält. Daneben gibt es eine andere Tile-Einheit, die Informationen über alle Bäume Neuköllns enthält. Zusammengesetzt mit einigen anderen Tiles bekommt man ein Raster von Tiles – ein sogenanntes Vector Tileset– das die geografischen Informationen über alle Bäume im Berliner Stadtgebiet enthält. Diese Tiles auf einer Karte zu rendern ist deutlich schneller als unser ursprünglicher Ansatz. Tiles sind auch der Ansatz, den viele große und kommerzielle Kartenanbieter wählen.
Wie kommt man von einer CSV-Datei zu einem Vector Tileset?
Für das Erstellen von Vector Tilesets gibt es verschiedene Wege, die wir innerhalb dieses Beitrags nicht im Detail erläutern können. Wichtig ist, dass die Ausgangsdaten – in unserem Fall das CSV der 800.000 Bäume – geografische Informationen enthalten, also zum Beispiel Längen- und Breitengrade für Punkte wie unsere Bäume oder Umrisse für geografische Gebiete. Das fertige Tileset muss dann auf einem Tileserver verfügbar gemacht werden.
Im CityLAB und in der Technologiestiftung Berlin benutzen wir für unsere Anwendungen teilweise externe Services als Tileserver, haben aber beispielsweise für das Projekt QTrees selbst einen Tileserver aufgesetzt.
Vector Tiles in Gieß den Kiez
Um unser Vector Tileset in Gieß den Kiez zu nutzen, war es nötig, den Code maßgeblich umzustrukturieren (auch “Refactoring” genannt) – ein Grund, warum wir diese Optimierung nicht schon früher umsetzen konnten. Das Vector Tileset einzubinden ist dann letzten Endes eine Sache von wenigen Zeilen Code.
Wer interessiert ist, kann sich die Funktionen ‘addSource‘ und ‘addLayer‘ im Source Code ansehen. Es muss hier lediglich eine URL zum Vector Tileset angegeben werden. Die geografischen Informationen innerhalb der Tiles können dann beliebig stilisiert werden. Wer Gieß den Kiez kennt, weiß zum Beispiel, dass die Bäume je nach Regenmenge einen anderen Grünton haben und ausgewählte Bäume rot umrandet angezeigt werden. Dies sind typische Style-Anpassungen für Objekte innerhalb des Vector Tilesets.
Was hat die Optimierung gebracht?
Wer heute Gieß den Kiez öffnet, wird merken, dass die Seite je nach Internetverbindung innerhalb von ein bis drei Sekunden lädt – für eine Ansicht von ganz Berlin mit allen 800.000 Bäumen ziemlich gut.
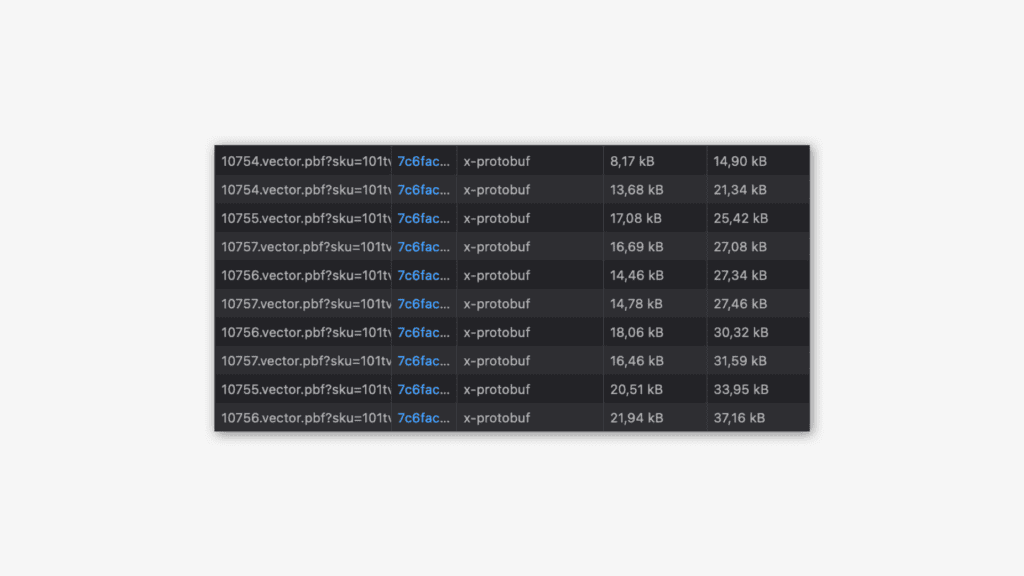
Im Network-Tab der Browser-Konsole kann man die Anfragen an die Vector Tiles sehen. Jede Tile-Einheit wird hier mit der Dateiendung .vector.pbf` geladen. Von diesen Anfragen gibt es viele. Jede davon überträgt aber nur kleine Datenmengen, nämlich immer nur die geografischen Informationen, die im jeweiligen Tile gespeichert sind. So wird sichergestellt, dass die Seite schnell lädt, denn es werden nur die Vector Tiles geladen, die für den aktuellen Kartenausschnitt und das Zoom-Level nötig sind. Vor wenigen Wochen hätte man hier noch eine einzelne Anfrage gesehen, die eine viele Megabyte große CSV-Datei übertragen hätte, mit anschließender rechenintensiver Weiterverarbeitung und Rendering der Daten auf der Karte.
Was wir gelernt haben
Gieß den Kiez entstand als schneller Prototyp in einem kleinen Design- und Development-Team. Über die Jahre haben wir immer mehr Erfahrungen mit Kartenanwendungen gesammelt und haben nun endlich die Ressourcen, unser neu gewonnenes Wissen in Gieß den Kiez einfließen zu lassen.
Heute können wir gut einschätzen, welche Datenmengen mit wenig Aufwand über eine simple CSV-Datei eingebunden werden können und ab wann Vector Tilesets die bessere Option sind. Bei neueren Projekten hilft uns das enorm. Der erste Prototyp im QTrees-Projekt zeigt beispielsweise die selben 800.000 Bäume wie Gieß den Kiez, ist allerdings von Anfang an optimiert über ein Vector Tileset eingebunden – schnellere Ladezeiten inklusive.
Bonus: andere Optimierungen für die Gieß-Community
Neben der Verbesserung der Gieß den Kiez-Ladezeiten hatten wir zuletzt auch Zeit, um einige weitere Verbesserungen anzugehen. In unserem öffentlichen Slack-Channel für Gieß den Kiez tragen Gießer:innen immer wieder Feedback und Wünsche an uns heran. Im letzten Herbstputz hatten wir Zeit, folgende Features einzubauen:
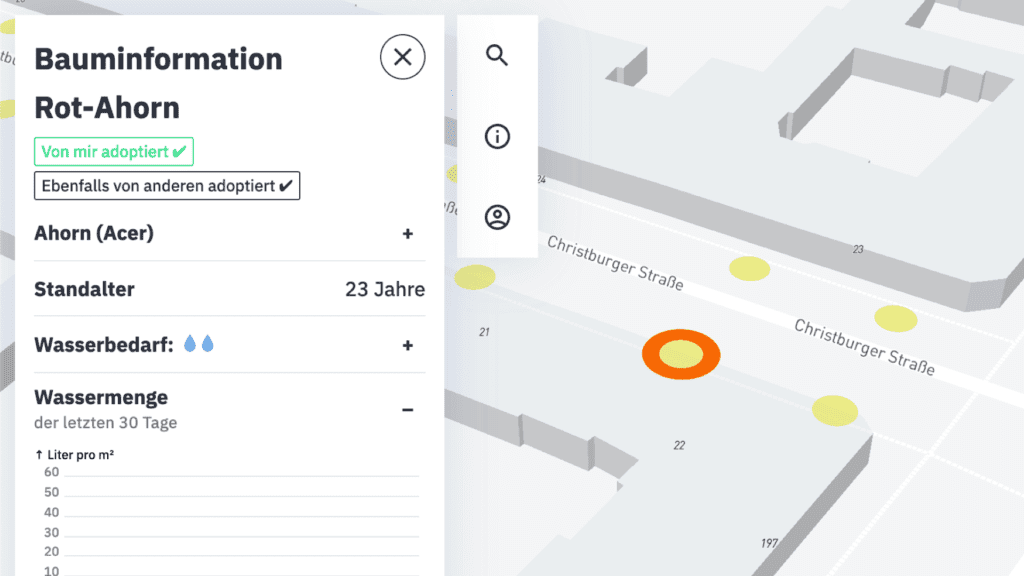
Jeder Baum hat nun einen kleinen Hinweis erhalten, ob er schon adoptiert wurde und somit bewässert wird. Ihr könnt sehen, ob ihr einen Baum selbst adoptiert habt oder ob andere ihn adoptiert haben. Das hilft, gegebenenfalls doppelte Pflege und Bewässerung der Bäume zu vermeiden.
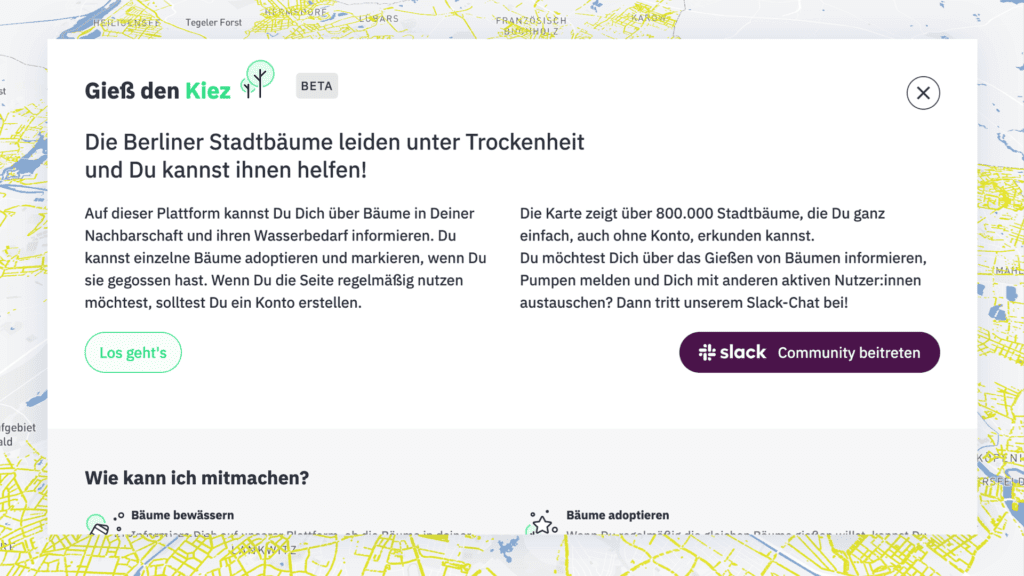
Um auch neuere Gießer:innen auf unseren Slack-Kanal aufmerksam zu machen, findet sich nun ein prominenter Link zum Community-Chat auf der Startseite. So ist es viel einfacher, sich anzumelden und sich mit anderen Gießer:innen aus der Stadt zu vernetzen.
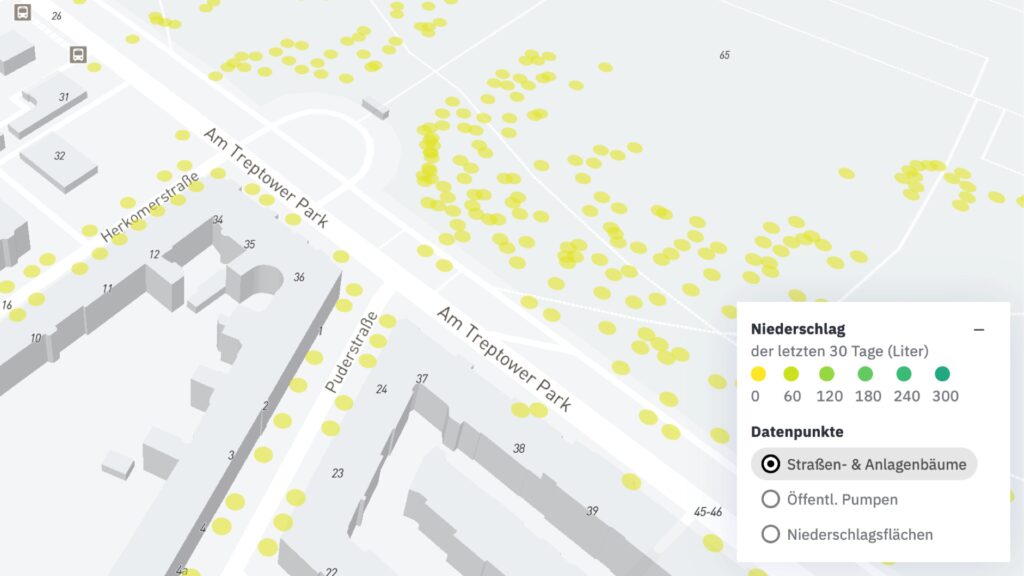
In der Legende können die verschiedenen Ebenen der Karte ausgewählt werden: Bäume, öffentliche Pumpen zum Wasser holen und Niederschlagsflächen. Nachdem die Auswahl und Erklärung vorher etwas kompliziert war, haben wir die Elemente nun vereinfacht und hoffen, dass dies die Karte leichter verständlich macht.
Wir freuen uns, dass das Gieß den Kiez weiterhin so gut von der Stadtgesellschaft angenommen wird und dass wir einen Beitrag dazu leisten können, mit dem kreativen Einsatz von Offenen Daten der Stadt Berlin, die Stadt für Natur und Mensch ein wenig lebenswerter zu gestalten. Wer Lust hat, die Bäume Berlins zu unterstützen, findet auf giessdenkiez.de und in unserem Slack-Kanal erste Hilfe.