The image of the male as the prototype of a human being is fundamental to the structure of our society. It is an ancient, deeply rooted tradition that extends as far as the theory of human evolution itself. Thus begins Caroline Criado-Perez’s book Invisible Women, in which she describes the gender data gap, a phenomenon that highlights the systematic omission of gender-specific data. This data gap results in inadequate coverage and representation of the realities of women’s and other genders’ lives – with far-reaching consequences in our data-driven world. Our colleague Ester Scheck of the Open Data Information Service (ODIS) looked into how Berlin’s open data is affected by the gender data gap: in this interview she talks about the impact of the data gap and ways to close it.

1. What are the implications of the gender data gap?
Ester: The gender data gap is a lack of data related to gender issues and perspectives – so it’s a general knowledge gap as well! Data is particularly lacking on the lived realities of women and queer individuals. By contrast, men have been viewed and continue to be viewed as the norm, and are overrepresented in the data landscape – in areas ranging from medical research to product testing. Specifically, this may mean that solutions developed based on this data simply do not work (well) for women and queer people. For example, most crash test dummies used to simulate car accidents are based on male body dimensions. Car safety features are therefore less adapted to female bodies, and women are also at a higher risk of injury statistically speaking.
2. To what extent can gender-specific data promote equality?
Ester: There are three types of gender data, and each type contributes to equality in a different way:
- Data collected and analyzed in a gender-differentiated manner, enabling the differences between the sexes to be made visible. This data helps identify where action is needed and enables monitoring of gender equality goals.
- Data on issues that particularly affect girls and women – for example, care work, female health, and sexual violence – and can therefore help solutions to be developed for this target group.
- Data showing the effect of socially constructed gender and gender norms on the sexes, thereby revealing structures that stand in the way of equality.
3. Why is this data lacking and how could our handling of data be improved
Ester: The lack of such data is not accidental: it is structural to our patriarchal society. Awareness of this is a fundamental requirement for the discrimination-sensitive handling of data. At the same time, the collection of such data supports the equality of different genders. In my opinion, all data that is somehow related to natural persons could and should be examined to see if there are gender differences – whether in the effects of environmental disasters or the tolerability of medication.
4. In what way do you think there is a link between open data and gender data?
Ester: There are a lot of people who talk about the benefits of open data, and there are some that point out the importance of gender data. But apart from individual data publication projects, little has been done to combine the two according to my research. Yet the two concepts have the capacity to feed into each other and reinforce the respective advantages: open data is more valuable if it deliberately describes diverse perspectives and realities of life. The potential of gender data to promote equality can be harnessed even more effectively if the data can also be analyzed and used outside the institution collecting the data. This increases transparency and creates new opportunities for participation and collaboration.
5. Can you give some specific examples where gender differences are visible through data?
Ester: The Gender Data Report issued by the Senate Department for Labor, Social Affairs, Gender Equality, Integration, Diversity and Anti-Discrimination offers some examples here. These also show clearly that gender data is not about proving that women are worse off than men. Society as a whole benefits from gender-specific data, since discrimination becomes visible, and the consequences and causes can be addressed in a way that is specific to the target group. And it is not just those examples that relate directly to individuals that are of interest, but also issues that affect men and women differently in general because of the differing realities of their lives. For example, girls may be disadvantaged where financial support is provided for sports clubs where the sport concerned is primarily pursued by boys as a result of societal norms. There are no data and analyses for Berlin on this yet unfortunately, but it shows that the gender relevance of data is often not directly visible.
6. What data did you look at in the course of your research and how did you go about it?
Ester: I looked at the metadata on the Berlin Open Data Portal and examined this for gender relevance. Metadata is information that describes a dataset – such as the publisher, title, tags, description and date of update. This data can be retrieved via CKAN API – a standardized programming interface on the data portal. At the time of my analysis in May, the data portal contained over 3,000 datasets, from which I first had to filter out the entries that referred to natural persons in order to examine direct gender references. For these entries, the title, description, and tags were checked for various gender keywords: woman/man, female/male, gender, sex.
If at least one of these keywords appeared, I assumed that the associated dataset was related to gender. In addition, to get an idea of what kind of entry was related to gender, I analyzed the categories, publishers, and tags. I programmed the API query and the analysis of the data in Python – here I got some help from my colleague Lisa. If anyone is interested in the details of this method, the script can be accessed online: people are free to use the code for similar analyses.
7. What did your analyses show?
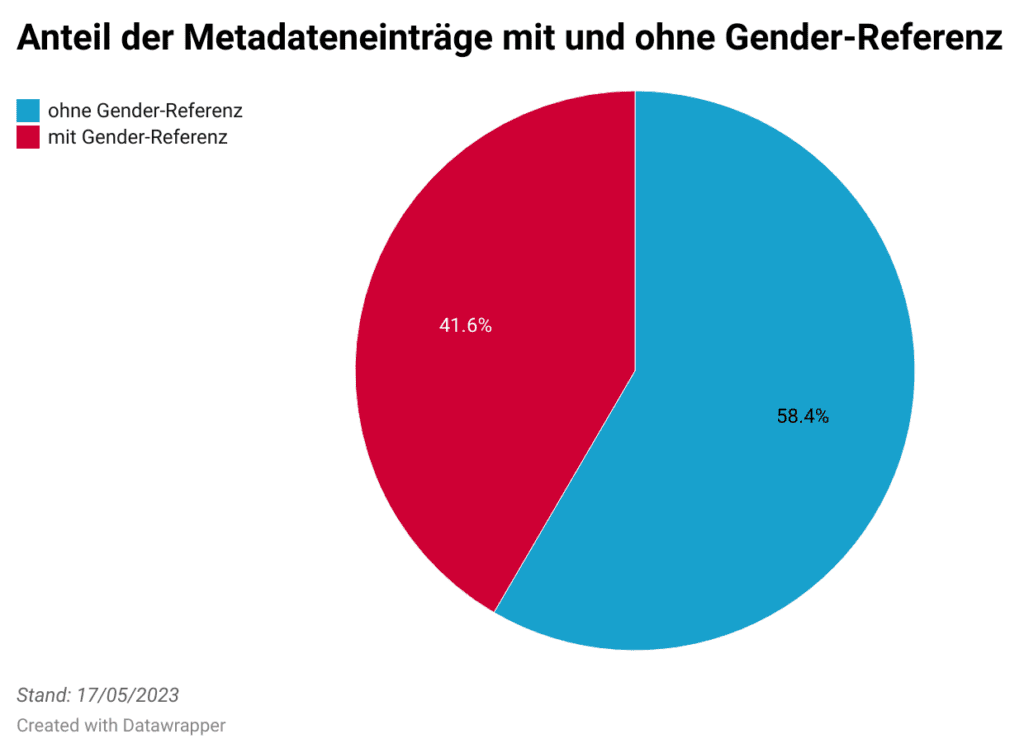
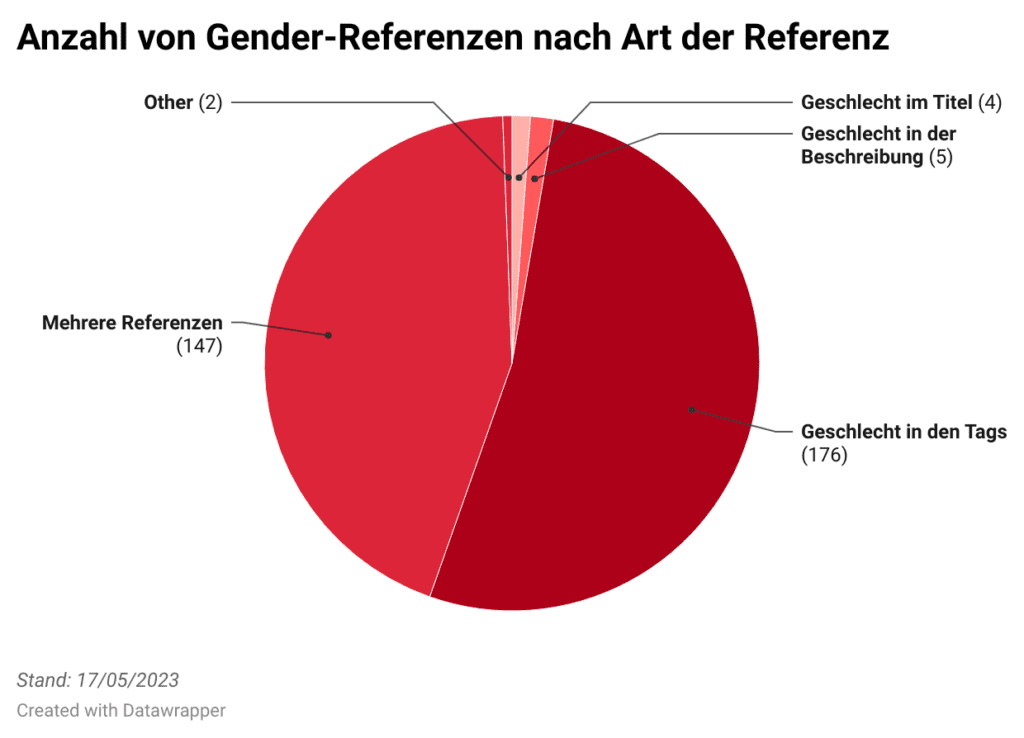
Ester: About a quarter of the entries in the data portal refer to natural persons, and of these, 41.6 per cent contain a gender reference. Unfortunately there are no comparative figures or benchmarks for this (yet), so it’s difficult to assess this figure. It’s more revealing to take a look at the nature of the gender references, as well as the categories and publishers. More than 95 per cent of the entries contain the keyword “sex”. The other keywords occur extremely rarely – gender in the socially constructed sense in particular still seems to receive little attention. In addition, the vast majority of gender-related entries are assigned to the data portal categories “Health” and “Social Services”; these are published by the Senate Department for Science, Health, Care and Equality, so they come from the Senate Department’s Health and Social Information System (GSI). It is striking that the Senate Department for Urban Development, Building and Housing is in second place in terms of publishers, but its identified dataset entries do not show any kind of gender reference. This could indicate that gender data should be strengthened in this context.
However, it’s very important to note that this analysis is based purely on the existing metadata and not on the datasets themselves. The metadata in the data portal are entered manually by different persons or fed in automatically from other portals (e.g. GSI, FIS-Broker), so they differ in terms of quality and volume. As such, the fact that dataset entries in the urban construction context – often geodatasets published via FIS-Broker – do not have a gender reference might also be due to the import of the metadata. I would have liked to apply the analysis directly to the datasets themselves instead of just examining the metadata, but this was unfortunately not possible within the scope of my research project due to their heterogeneity and sheer volume.
8. What do you think could be improved in the collection of the data
Ester: I think collecting gender data varies quite a bit from context to context and is definitely challenging. It’s important to act sensitively and responsibly when collecting data – and ideally ask yourself the following questions: What gender identities beyond the binary genders of woman and man need to be considered? What is the real issue – biological sex or gender in the socially constructed sense? How can extraneous attributions be avoided? How can the data be collected without simultaneously manifesting discrimination and stigmatization? Which other “categories” should be analyzed in a broader context so as to reveal other forms of discrimination such as racism or ableism and the intersections between them (cf. intersectionality) in quantitative terms? Where might quantitative surveys not be appropriate? And how can this personal information be used and published responsibly? All of these questions about data collection describe yet another huge field where research in areas such as gender studies has already done great work.
10. Where can I read more about this?
Ester: I recommend the following books on the subject:
- https://carolinecriadoperez.com/book/invisible-women/
- https://www.dumont-buchverlag.de/buch/endler-das-patriarchat-9783832170912/
- https://mitpress.mit.edu/9780262044004/.”
Thank you, Ester, for sharing these insights into your research! More information is available in this blog post published by the Open Data Information Service.