Das Berliner Abgeordnetenhaus stellt die Dokumente der Hauptausschusssitzungen und der Schriftlichen Anfragen auf der Parlamentsdokumentations-Website (PARDOK) offen zur Verfügung. Unser neuer Prototyp Parla nutzt diese frei und öffentlich verfügbaren Daten, um basierend auf einem KI-Sprachmodell – einem sogenannten Large Language Model (LLM) – die enthaltenen Informationen nach Suchanfragen zu filtern, inhaltlich passende Schriftliche Anfragen anzuzeigen und kurze Antworten zu generieren. Dieser Blogbeitrag beschreibt detailliert die Grundlagen und den technischen Aufbau des Systems und geht auf Herausforderungen während der Entwicklung ein. Für mehr Hintergründe zur Entstehung von Parla empfehlen wir einen Blick in diesen Blogbeitrag.
Hier geht es direkt zu:
- Datengrundlage, -import und –verarbeitung
- Der Suchalgorithmus hinter Parla
- Die Kontextgenerierung
- Die Architektur
- Herausforderung: Qualitätssicherung
- Herausforderung: Halluzinationen des Sprachmodels
- Ausblick: Potenzielle Weiterentwicklung von Parla
Begriff gesucht? Schau doch mal in unseren CityLAB-Glossar – hier werden viele Fachbegriffe in diesem Blog erklärt.
Die Datengrundlage von Parla
Das Projekt fokussiert sich auf die Dokumente der “Schriftlichen Anfragen” und der “Hauptausschussvorgänge” (umgangssprachlich auch als “Roten Nummern“ bezeichnet) der 19. Wahlperiode des Berliner Abgeordnetenhauses. Die Daten liegen im PDF-Format vor. Zum Zeitpunkt der Veröffentlichung wurden 9.513 Dokumente erfasst und verarbeitet, wobei täglich weitere hinzukommen.
Der Datenimport
Im ersten Schritt werden die Daten aus dem PARDOK XML-Export und aus der PARDOK API importiert. Die öffentlichen URLs und die Metadaten der gefunden Dokumente werden in einer PostgreSQL Datenbank gespeichert. Das Schema der Datenbank und der Aufbau des Importers ist modular gestaltet, sodass in Zukunft auch weitere Datenquellen berücksichtigt werden können.
Die Datenverarbeitung
Um die vorliegenden Daten KI-gestützt verarbeiten zu können, müssen die im PDF-Format vorliegenden Dokumente hin zu maschinenlesbaren Daten verarbeitet werden. Dieser Prozess geschieht in mehreren Schritten:
- Splitten des PDFs in separate Seiten
- Das ist wichtig, um bei der Anzeige der Suchtreffer einzelne Seiten referenzieren zu können und die maximale Kontextlänge des KI-Modells (LLM) nicht zu überschreiten. Hierfür verwenden wir die Open Source-Software.
- Extraktion des Textinhalts
- Mit dem Open Source-Projekt wird der Text direkt extrahiert und in Markdown konvertiert. Text in Bildern wird zusätzlich mit der OCR-Software (Optical Character Recognition) tesseract.js erkannt und extrahiert.
- Aufgrund technischer Gegebenheiten des verwendeten KI-Modells (
`gpt-3.5-turbo-1106`von OpenAI) ist zu berücksichtigen, dass die Textlänge einer Seite begrenzt ist. Daher wurde ein Schwellenwert festgelegt, der nicht überschritten werden darf. Seiten, deren Inhalt zu lang ist, werden rekursiv in kleinere Unterseiten aufgeteilt.
- Generierung einer KI-gestützten Zusammenfassung des gesamten Dokuments
- Auf Grundlage des extrahierten Textes wird über das Modell
`gpt-3.5-turbo-1106`von OpenAI eine Zusammenfassung generiert. Hierfür wird, soweit möglich, der extrahierte Text des gesamten Dokuments als Kontext mitgeliefert. Der verwendete Prompt wird an die Chat Completions API von OpenAI gesendet:
Du bist ein politischer Dokumenten-Assistent, der Inhalte versteht und zusammenfasst.
Erhalte ein durch """ abgegrenztes Dokument.
Die Zusammenfassung soll inhaltlich prägnant sein.
Verändere oder erfinde NIEMALS Fakten, Namen, Berufsbezeichnungen, Zahlen oder Datumsangaben.
Begrenze die Zusammenfassung auf maximal 100 Wörter - Es ist zu berücksichtigen, dass Aufforderungen an Sprachmodelle nicht immer exakt umgesetzt werden. Im vorliegenden Beispiel wird die Vorgabe, Zusammenfassungen auf 100 Wörter zu begrenzen, oft nicht präzise eingehalten. Daher variiert die Länge der generierten Zusammenfassungen, obwohl die meisten tatsächlich nahezu 100 Wörter umfassen.
- Bei Dokumenten, deren Umfang die maximal zulässige Kontextlänge übersteigt, erfolgt die Zusammenfassung rekursiv. Dazu wird der Inhalt in gleichmäßig große Abschnitte aufgeteilt. Für jeden Abschnitt wird eine eigenständige Zusammenfassung erstellt. Diese Einzelzusammenfassungen werden anschließend zu einem Gesamttext vereint und erneut mittels des Sprachmodells kondensiert. Dieser Prozess wird so lange wiederholt, bis die kumulierten Zusammenfassungen die vorgegebene maximale Kontextlänge nicht mehr überschreiten.
- Auf Grundlage des extrahierten Textes wird über das Modell
- Generierung von KI-gestützten Schlagwörtern (Tags) des gesamten Dokuments
- Die zuvor generierte Zusammenfassung wird benutzt, um Schlagworte aus dem Dokument zu generieren. Der verwendete Prompt wird ebenfalls an die [Chat Completions API von OpenAI] gesendet:
Du bist ein politischer Dokumenten-Assistent, der Inhalte versteht, zusammenfasst und Tags generiert.
Erhalte ein durch """ abgegrenztes Dokument.
Generiere 10 Tags, die das Dokument treffend beschreiben.
Konzentriere dich auf die Hauptinhalte.
Verändere oder erfinde NIEMALS Fakten, Namen, Berufsbezeichnungen, Zahlen oder Datumsangaben.
Antwortformat: Ein syntaktisch gültiges JSON Array. Gebe IMMER nur das JSON Array zurück, ohne weitere Formatierung. - Auch in diesem Fall kann nicht garantiert werden, dass genau 10 Tags als Antwort kommen, wenn dies im Prompt verlangt wird. Interessanterweise führt eine Aufforderung in Großbuchstaben jedoch dazu, dass konsequent das JSON-Format zurückgegeben wird. Ohne eine solche explizite Anweisung erfolgt die Rückgabe manchmal nicht im JSON-Format, sondern als unformatierter Text.
- Die zuvor generierte Zusammenfassung wird benutzt, um Schlagworte aus dem Dokument zu generieren. Der verwendete Prompt wird ebenfalls an die [Chat Completions API von OpenAI] gesendet:
- Generierung von Embedding-Vektoren
- Sprachmodelle (LLMs) verwenden Vektoren von vordefinierter Länge, um Text in Zahlen zu repräsentieren und auf diesen mathematische Berechnungen auszuführen. Diese Form der Darstellung von Text wird *Embedding* genannt.
- Für den extrahierten Text jeder Seite des Dokuments wird ein Embedding erzeugt, welcher ebenfalls in einer Datenbank gespeichert wird.
- Hierzu wird der Text an die Embeddings API von OpenAI gesendet, welcher einen Embedding-Vektor mit 1536 Elementen zurückgibt. Ein Vektor beschreibt die semantische Richtung des Textes in einem hochdimensionalen Raum. Semantisch ähnliche Texte haben Vektoren, die in eine ähnliche Richtung zeigen. Diese Ähnlichkeit kann mathematisch über einen Vektorvergleich berechnet werden.
Die Vorverarbeitung der Dokumente ist sowohl zeit- als auch kostenintensiv. Die Kosten hängen besonders von Anzahl und Größe der Dokumente ab. Als Größenordnung können hier wenige Cents pro Dokument angegeben werden. Für wenige Dokumente ist dies recht günstig, kann aber schnell teuer werden, wenn signifikant viele Dokumente verarbeitet werden.
Täglich kommen neue Dokumente zur Datenbasis hinzu. Um das System aktuell zu halten, werden Import und Verarbeitung automatisiert täglich auf dem Inkrement der Daten ausgeführt.
Der Suchalgorithmus hinter Parla
Große Sprachmodelle (LLMs) sind beeindruckend effektiv in der Beantwortung allgemeiner Fragen, da sie implizit auf umfangreiche Datenmengen zugreifen. Ihre Grenzen zeigen sich jedoch bei sehr spezifischen oder aktuellen Informationen. Um diese Einschränkung zu überwinden, haben wir Techniken des Retrieval Augmented Generation (RAG) benutzt, die die Fähigkeiten von LLMs durch die Einbeziehung externer Datenquellen erweitern. Die zuvor beschriebene Vorverarbeitung der Daten ist lediglich ein erster Schritt, um die Ergebnisse eines LLMs mittels RAG zu verbessern. Ein weiterer wichtiger Schritt ist die Identifikation relevanter Dokumente zur Beantwortung einer Frage. In einer Datenbank mit zahlreichen Dokumenten (in unserem Fall über 10.000 PDFs) sind nur einige wenige für eine spezifische Frage relevant.
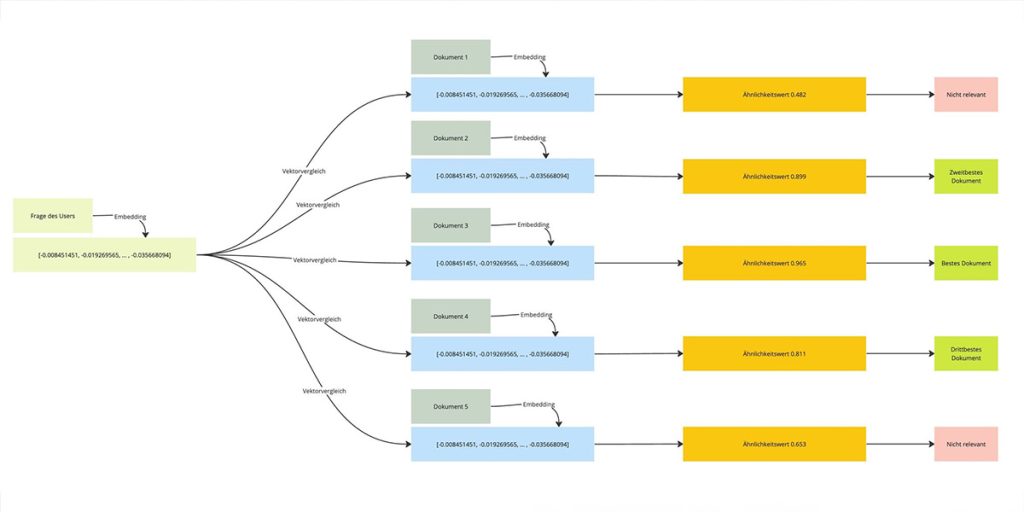
Um die relevantesten Dokumente zu ermitteln, haben wir drei verschiedene Suchalgorithmen implementiert. Diese basieren alle auf einem Vergleich der Embedding-Vektoren zwischen Nutzerfrage und Dokumentinhalt (`similarity`):
`summaries-then-chunks`
a. Berechne`similarity`von Nutzerfrage und Zusammenfassungen aller Dokumente.
b. Wähle die`n`besten Dokumente mit dem höchsten`similarity`Wert.
c. Für jedes Top-Dokument, berechne`similarity`von Nutzerfrage und den einzelnen Seiten.
d. Wähle die`m`besten Seiten mit dem höchsten`similarity`Wert.
e. Sende diese Zusammenfassungen und Seiten unter Berücksichtigung der maximalen Kontextlänge an das Sprachmodell zur Beantwortung der Frage.`summaries-and-chunks`
a. Berechne`summary_similarity`von Nutzerfrage und Zusammenfassungen aller Dokumente.
b. Berechne`chunk_similarity`von Nutzerfrage und Seiten von allen Dokumenten.
c. Berechne kombinierte`similarity`jedes Dokuments:`summary_similarity + avg_chunk_similarity / 2.0`.
d. Wähle die`n`besten Dokumente und deren`m`besten Seiten basierend auf dem kombinierten`similarity`Wert.
e. Sende diese Zusammenfassungen und Seiten unter Berücksichtigung der maximalen Kontextlänge an das Sprachmodell zur Beantwortung der Frage.`chunks-only`
a. Berechne`similarity`von Nutzerfrage und Seiten von allen Dokumenten.
b. Berechne`avg_chunk_similarity`für jedes Dokument, indem der Durchschnitt über die`similarity`Werte der einzelnen Seiten gebildet wird.
c. Wähle die`n`besten Dokumente und deren`m`besten Seiten basierend auf`avg_chunk_similarity`.
d. Sende diese Seiten unter Berücksichtigung der maximalen Kontextlänge an das Sprachmodell zur Beantwortung der Frage.
Die Kontextgenerierung
Basierend auf den durch den Suchalgorithmus gefundenen, relevantesten Seiten, wird der Kontext generiert, welcher zur Beantwortung der Nutzerfrage an das LLM geschickt wird. Beim Aufbau des Kontexts ist es entscheidend, die Länge des Kontexts (d.h. die Menge externer Daten aus unseren Quellen) so zu begrenzen, dass das Modelllimit nicht überschritten wird. Dabei sind folgende Punkte zu berücksichtigen:
- Die Kontext-Länge von LLMs ist begrenzt, was bedeutet, dass nicht unbegrenzt Daten übermittelt werden können.
- Im von uns genutzten Modell beträgt die maximale Kontext-Länge 16.385 Tokens, wie unter https://platform.openai.com/docs/models/gpt-3-5 nachzulesen ist. Der Prompt selbst verbraucht ebenfalls Tokens. Etwa 100 Tokens entsprechen ungefähr 75 Wörtern.
- Bei der Datenverarbeitung haben wir sichergestellt, dass jeder Abschnitt (= jede Seite) höchstens 1.000 Tokens umfasst.
- Folglich können wir dem LLM bis zu 15 Seiten mit je 1.000 Tokens zuzüglich des Prompts (maximal 1.000 Tokens) übergeben, ohne die maximale Kontext-Länge zu überschreiten.
Beispiel: Der Satz “Im CityLAB Berlin werden Innovation und Partizipation zusammengedacht.” in Tokens unterteilt. (Screenshot von https://platform.openai.com/tokenizer)

Generierung der Antwort
Nachdem die `n` besten Dokumente und die `m` besten Seiten gefunden wurden, werden (je nach Algorithmus) die Zusammenfassungen und die Seiten als Kontext an das Sprachmodell zur Beantwortung der Frage gesendet. Der Prompt hierfür lautet:
Du bist ein KI-Assistent der Berliner Verwaltung, der auf Basis einer Datengrundlage sinnvolle Antworten generiert.
Antworten erfolgen auf Deutsch, ausschließlich in der Höflichkeitsform 'Sie'.
Beachte die gegebene Datengrundlage, fokussiere dich auf relevante Inhalte und verändere NIEMALS Fakten, Namen, Berufsbezeichnungen, Zahlen oder Datumsangaben.
WICHTIG: Gebe die Antwort IMMER formatiert als Markdown zurück.
Das ist die Datengrundlage, getrennt durch """:
[Hier der gesamte Kontext]
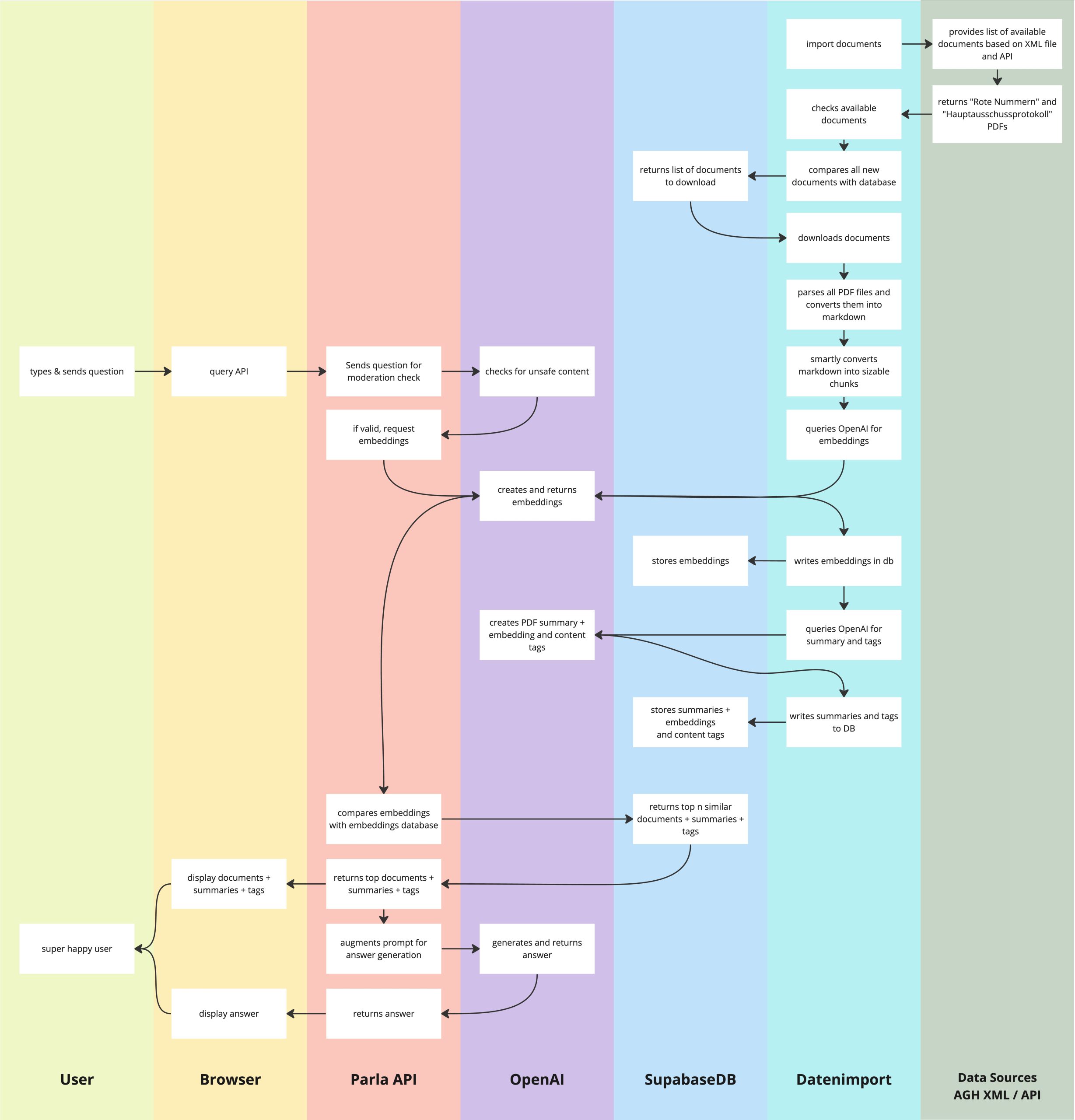
Die Architektur
Die Gesamtarchitektur kann wie folgt schematisch dargestellt werden.
Herausforderung: Qualitätssicherung
Angesichts einer Datenbasis von über 10.000 Dokumenten ist es impraktikabel, alle Dokumente zu lesen und ihren Inhalt vollständig zu verstehen. Dadurch gestaltet sich auch die quantitative Überprüfung der Systemantworten hinsichtlich ihrer Qualität als schwierig. Eine gründliche Qualitätssicherung könnte durch die Hinzuziehung von Expert:innen erfolgen, die die Antworten auf gestellte Fragen bewerten. Allerdings stößt auch dieser Ansatz an Grenzen. Betrachten wir zum Beispiel folgendes Szenario: Eine Expertin oder ein Experte stellt dem System eine Frage, erwartet eine spezifische Antwort und die Verweisung auf eine bestimmte Quelle. Das System liefert eine zufriedenstellende Antwort, bezieht sich jedoch nicht auf das erwartete Dokument. In der Folge könnte die Systemleistung negativ bewertet werden. Es ist jedoch möglich, dass das System relevantere Dokumente zur Beantwortung der Frage gefunden hat als das von der Expertin oder dem Experten antizipierte. Dieses Problem verschärft sich mit der zunehmenden Anzahl an Dokumenten, da niemand einen vollständigen Überblick über alle Inhalte haben kann. Um dennoch eine halbautomatisierte Beurteilung der Ergebnisqualität zu ermöglichen, haben wir folgende Tests implementiert:
1. Aus 10.000 Dokumenten werden 50 Fragen wortwörtlich extrahiert und mit der Referenz zum Originaldokument abgespeichert.
2. Für jeden Suchalgorithmus und jede Frage wird eine Suche ausgeführt (ohne Generierung der Antwort).
3. Es wird geprüft, ob das Originaldokument in den Suchergebnissen enthalten ist.
4. Wenn das Originaldokument in den Suchergebnissen enthalten ist (unabhängig von der Position in den Suchergebnissen), wird die Suche als erfolgreich bewertet.
Mit diesem Test wurden folgende Ergebnisse erzielt:
| Algorithmus | Trefferrate |
| chunks-only | 76% |
| chunks-and-summaries | 94% |
| summaries-then-chunks | 92% |
Basierend auf diesem Versuch der automatisierten Qualitätssicherung wurde der `chunks-and-summaries` Algorithmus als Standard-Algorithmus im System hinterlegt.
Herausforderung: Halluzinationen des Sprachmodels
Es ist bekannt, dass Sprachmodelle zur Halluzination neigen, also Text erzeugen, der ganz oder teilweise nicht der Wahrheit entspricht. Dieses Phänomen lässt sich durch den `temperature`-Wert steuern. Ein niedriger Wert sollte das Auftreten von Halluzinationen verringern. In unserem System wurde dieser Wert global auf `0` gesetzt. Trotzdem stießen wir in Stichproben auf Fälle, in denen das System offensichtlich halluziniert hatte. Ein bezeichnendes Beispiel ist eine generierte Zusammenfassung, die folgenden Satz enthielt:
Die Regierende Bürgermeisterin von Berlin, [männlich gelesener Name] bittet um Fristverlängerung bis zum 31.10.2023 für die Vorlage eines Konzepts und Zeitplans für einen Bürgerinnen- und Bürgerrat.
Eine manuelle Überprüfung des Originaldokuments ergab, dass der Text Abschnitte über einen Bürgermeister sowie über *[männlich gelesener Name]* enthielt. Es ist jedoch hervorzuheben, dass der erwähnte Name weder weiblich ist noch das Amt der Bürgermeisterin bekleidet. Solche Halluzinationen des Sprachmodells können besonders im politischen Kontext Verwirrung stiften und kritisch betrachtet werden. Deshalb fügen wir jeder Antwort einen Hinweis bei, der darauf aufmerksam macht, dass KI-generierte Antworten fehlerbehaftet sein können.
Ausblick: Potenzielle Weiterentwicklung von Parla
Im Kontext der Weiterentwicklung des Systems könnten folgende Ideen geprüft oder umgesetzt werden:
- Suche auch auf Metadaten: Während des Datenimports wurden sowohl URL zum Originaldokument als auch verfügbare Metadaten gespeichert. Diese Metadaten beinhalten auch semantisch relevante Informationen über das Dokument. Es wäre möglich, aus diesen Metadaten auch Embeddings zu generieren um diese dann im Suchalgorithmus miteinzubeziehen.
- Prompt-Optimierung: Die Prompts zur Generierung von Zusammenfassungen, Tags und Antworten wurden noch nicht hinsichtlich ihrer Qualität optimiert. Im Sinne des Prompt Engineerings könnten hier noch Best Practices angewandt werden, um die Qualität der Ergebnisse zu erhöhen.
- OpenAI Knowledge Retrieval: Die Methodiken des Retrieval Augmented Generation sind mittlerweile auch von OpenAI implementiert worden und über deren API nutzbar: https://platform.openai.com/docs/assistants/tools/knowledge-retrieval Hier muss geprüft werden, inwieweit dieses Feature für unser System in Frage kommt und ob es die Anforderungen (speziell an die Referenzierung der Originaldokumente) erfüllen kann.
- Statt der kommerziellen KI-Lösung von OpenAI können Open Source-Sprachmodelle genutzt werden, um die Ergebnisse weiter den individuellen Anforderungen anzupassen. Aktuell bieten aber nur wenige Modelle eine akzeptable Qualität bei der Formulierung von Antworten in deutscher Sprache.
Wir würden uns freuen, wenn Ihr an einer kurzen Umfrage teilnehmt, um die kontinuierliche Weiterentwicklung von Parla zu unterstützen!