Ausgangslage
Welche Nachhaltigkeitsziele verfolgt der Berliner Senat mit Blick auf die Reduzierung des CO2-Ausstoßes? Wie wirkt sich der Mangel an Lehrkräften aus? Welche Initiativen gibt es, um den kulturellen Sektor in Berlin zu unterstützen? Auf Fragen wie diese liegen bereits konkrete Antworten vor – in Form der sogenannten Schriftlichen Anfragen. Schriftliche Anfragen sind ein zentrales Instrument unserer Demokratie und erlauben es, die Regierung oder staatliche Stellen zum konkreten Stand oder zu spezifischen Informationen von öffentlichen Maßnahmen zu befragen. Üblicherweise richten sich jene Anfragen an die Senatsverwaltungen in Berlin und werden von den entsprechenden Senatsmitgliedern oder beauftragten Behörden beantwortet.
Die öffentliche Verwaltung verarbeitet täglich große Mengen an Informationen, verfügt jedoch in weiten Teilen über kein digitales Wissensmanagement. Daten und Dokumente werden nicht zentral und einheitlich gespeichert, sondern liegen verteilt in unterschiedlichen Systemen, Datenbanken, Excel-Dateien, Protokollen oder Vermerken. Entsprechend viel Zeit verbringen Beschäftigte der Berliner Behörden damit, Informationen aus verschiedenen Quellen anlassbezogen zusammenzustellen und aufzubereiten.
Mit unserem Prototypen Parla erproben wir die Möglichkeiten, diesen Prozess der Informationsgewinnung durch Künstliche Intelligenz zu unterstützen. Das manuelle Suchen nach einer bestimmten Information, die in einem der zahlreichen Sitzungsprotokolle erwähnt ist, kann so perspektivisch entfallen. Aber auch Bürger:innen und Unternehmen, die sich für aktuelle Entwicklungen in ihrem Umkreis oder ihrer Stadt interessieren, können über Parla leichter Zugang zu Informationen erhalten.
Wie funktioniert Parla?
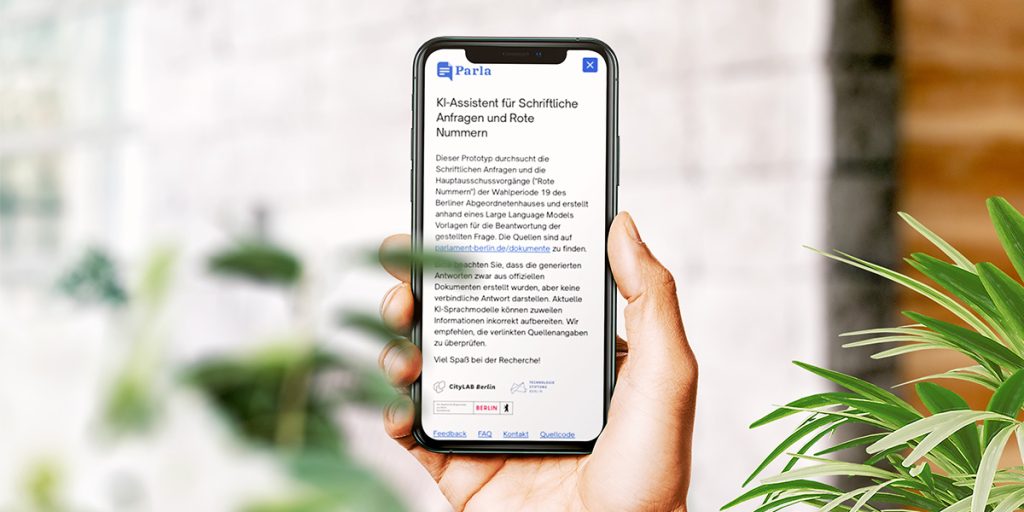
Parla hat Zugriff auf mehr als 19.500 öffentlich verfügbare Dokumente, die auf dem parlamentarischen Dokumentationssystem PARDOK in der laufenden Wahlperiode publiziert wurden. In der aktuellen Version umfasst der Textkorpus neben sämtlichen Antworten auf Schriftliche Anfragen von Abgeordneten auch die wichtigen Hauptausschussvorgänge (sogenannte „Rote Nummern“). Stellt man Parla eine Frage, formuliert das System auf dieser Textgrundlage einen Antwortvorschlag und referenziert die dafür genutzten Dokumente, sodass die Nachvollziehbarkeit gewährleistet bleibt.
Parla kann so nicht nur die tägliche Arbeit von Parlament und Verwaltung digital unterstützen. Auch für viele andere Akteure, etwa für Verbände, Kammern, Medien und zivilgesellschaftliche Organisationen ist es oft aufwändig, einen Überblick über aktuelle Sachverhalte und Beschlusslagen zu erhalten.
Die Beantwortung von parlamentarischen Anfragen ist oft sehr zeitaufwendig, bei den notwendigen Recherchearbeiten spart uns Parla bis zu 40% an Zeit.
Tristan Pfarr, Leitungsstab – Stab S P 1 der Berliner Feuerwehr
In unseren Tests hat sich Parla als hilfreich für eine Vielzahl von Anwendungsfällen erwiesen. Dennoch arbeitet auch unser System nicht immer fehlerfrei. Es ist inzwischen bekannt, dass große Sprachmodelle mitunter Informationen falsch interpretieren und nicht akkurat wiedergeben können. Unser Prototyping-Team hat intensiv daran gearbeitet, diese sogenannten „Halluzinations“-Probleme zu minimieren – ganz ausschließen lassen sie sich aber beim aktuellen Stand der Technik nicht. Es ist deshalb grundsätzlich sinnvoll, die von Parla generierten Antworten mit Hilfe der referenzierten Dokumente zu überprüfen.
Durch den Einsatz eines Large Language Models (LLM) kann der Prototyp die zur Suchanfrage passenden Dokumente herausfiltern und Kurzantworten generieren. Die Datenbasis des Tools wird täglich aktualisiert, um die Relevanz und Aktualität der Informationen sicherzustellen. Mehr Einblicke in den technischen Hintergrund von Parla teilen wir in diesem Blogbeitrag.
Wie geht es weiter?
Parla stellt derzeit ein Experiment mit KI und dem Einsatz in der Verwaltung als eine fertige Lösung dar. Genau das macht unseren agilen Prototpying-Ansatz im CityLAB aus: Hindernisse und Hürden auf dem Weg zu einer fertigen Lösung sichtbar zu machen, um daraus weitere Schritte abzuleiten.
Parla macht auf diese Weise zum Beispiel deutlich, wie wichtig es für Verwaltungen ist, gut strukturierte, maschinenlesbare Daten- und Metadatenbestände aufzubauen und zu pflegen. Die Qualität einer KI-generierten Antwort kann letztlich nur so gut sein wie die Datengrundlagen, die der KI zur Verfügung stehen. Diese Datengrundlagen sind in den meisten Verwaltungen – vorsichtig formuliert – ausbaufähig.
Insbesondere für die Verwaltungsarbeit wäre es zudem hilfreich, Parla um weitere, auch verwaltungsinterne Dokumente zu ergänzen. Aus Gründen des Datenschutzes und der Informationssicherheit ist dies jedoch zurzeit nicht möglich. In der jetzigen Form hat Parla kein Problem mit Datensicherheit, weil es sich ausschließlich auf Dokumente stützt, die bereits öffentlich zugänglich und gemeinfrei sind. Um interne Dokumente sicher verarbeiten zu können und die Datenhoheit zu behalten, müsste das Land Berlin aber vermutlich ein Sprachmodell auf eigener Infrastruktur betreiben – ein Schritt, der für die Zukunft ernsthaft in Betracht gezogen werden sollte.
Der Source Code von Parla kann auf GitHub eingesehen und weiterverwendet werden.
Wir würden uns freuen, wenn ihr an einer kurzen Umfrage teilnehmt, um die kontinuierliche Weiterentwicklung von Parla zu unterstützen!
Beteiligte
CityLAB Berlin
Abgeordnetenhaus Berlin
Senatskanzlei Berlin
Kontakt
Ingo Hinterding (Product Lead / Teamleitung Prototyping & Forschungsprojekte)